Deploying multi-tenant machine learning models on AWS
An overview of the best architectures and methods of deploying SaaS machine learning applications with SageMaker Inference.
 Amazon SageMaker
Amazon SageMaker AWS Step Functions
AWS Step Functions

Business intelligence SaaS platforms are springing up like mushrooms, due to the increasing importance of data-driven management. Machine Learning is used in every domain to provide stakeholders with valuable insights. But deploying a trained machine learning model to bespoke software is not the same as deploying it in a SaaS environment.
Common SaaS architectures
The architectures of software as a service applications are vastly different from those used in typical bespoke software. Such products are designed to be delivered to multiple customers through isolated instances sourced from a central codebase and infrastructure. Each instance needs to be served to each of the hundreds or thousands of tenants.
To give you a relatable SaaS example, us IT folks use SaaS on a daily basis (sometimes unknowingly). GitHub, Slack, Jira, Teams, Chime are all great examples of SaaS applications. Our companies have our own instances with our data, users, chats, repositories and projects, but the product and feature set underneath stays mostly the same.
But the actual independence of a product instance can vary. Even though our application is separate from other tenants (i.e. we are not able to access their users and data), the underlying infrastructure may not be. It is up to the SaaS vendor if resources are shared or not.
Generally speaking, three main kinds of architectures are used:
- A Silo model where every part of the infrastructure is completely separate from every other tenant. In AWS terms this usually means each customer has their own AWS Account with their own containers, EC2s, Lambdas, load balancers, databases and so on. This gives the highest level of separation and security, but is quite costly, especially in non-serverless applications. Vendor sometimes even allows you to deploy it on your own on premises as well.
- At the other end of the spectrum, we’ve got a Pool model where everything is shared between all tenants. There’s one AWS Account, shared web and application layer as well as a shared (but usually sharded) data store. Economy of scale kicks in, as adding a new tenant is rather cheap. This comes with its own cons and challenges like a noisy neighbor problem, where a high utilization of one tenant may negatively impact the user experience of the other tenants.
- Somewhere in between lies a Bridge model, a mix of both worlds. Some pieces like application containers and compute machines are shared while some are not (usually data stores).
To avoid confusing everyone with the word model, which could either mean “a machine learning model” or a “SaaS architecture model (silo/bridge/pool)”, we will just use Silo, Bridge and Pool from now on.
Machine learning and SaaS
Silo, Bridge and Pool are universal and are not bound to specific use cases or domains. This means that if we are building our own SaaS that is powered by Machine Learning, we’ll inevitably have to make a (crucial) choice between them.
With Business Intelligence applications, the machine learning model could be simultaneously used by hundreds or thousands of tenants. How do we ensure that the latency, performance and availability are top-notch? With other types of SaaS solutions, every tenant could have their own model trained by a SaaS vendor. But deploying each of them on a separate machine might be too costly and require too much maintenance effort. Additionally, some platforms generate predictions periodically, while others do it in near-real time. How do we balance that? And how do we pick the right deployment method if we went with Silo, Bridge or Pool?
This article will showcase Amazon SageMaker and its SageMaker Inference service used to deploy machine learning models. We also mention if a given method is compatible with Silo, Bridge or Pool.
Note that the model training can be done outside of AWS with your custom algorithms and containers. You can freely train your models elsewhere and use AWS to deploy them.
Batch transform
Batch transforms work best in a Bridge or Pool with a shared machine learning model, but they can also be successfully used in Silo and with tenant-specific models.
If you plan on building a business intelligence SaaS that provides insights on a daily, weekly or monthly basis, this one was meant for you. What you need is a scheduled, batch prediction mechanism which will periodically use your trained models on each tenant’s dataset. And this is exactly what Batch Transform does.
Especially when you’re sharing the machine learning model between all your tenants, this is a breeze:
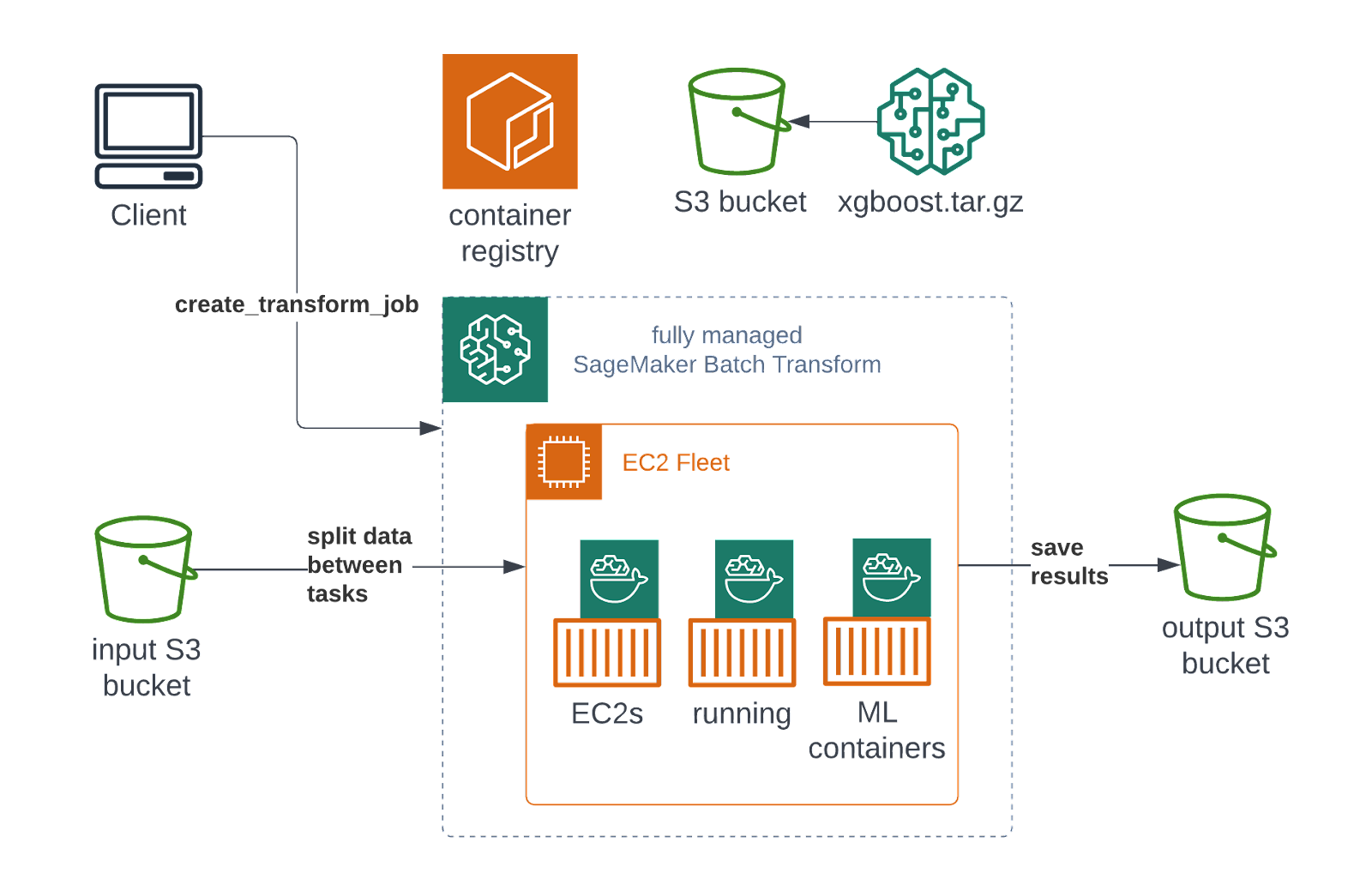
All you have to do is to prepare your datasets in the form of files. Amazon SageMaker Batch Transform will manage everything for you. First, a cluster of specified machines with a model (in this example - XGBoost) is created. Then, your tenants’ data is shuffled between machines and an inference is performed. Lastly, results are saved and the cluster will be shutdown. Your dashboards can then query resulting files for the insights to visualize them.
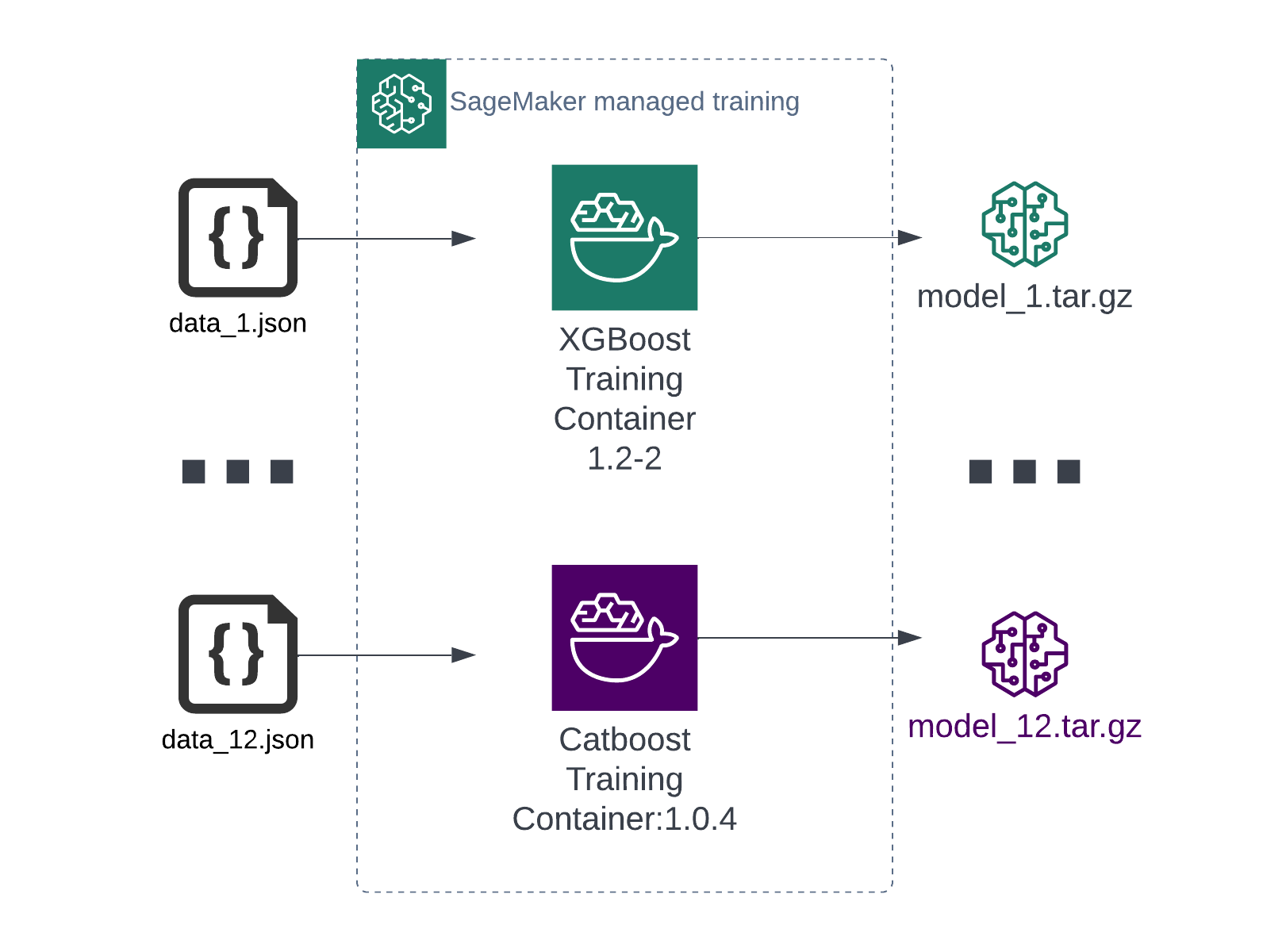
Each tenant having their own, tailored model is a more common scenario. In this case, the model is typically based on the same algorithm, but trained on different datasets. This can be illustrated as follows:
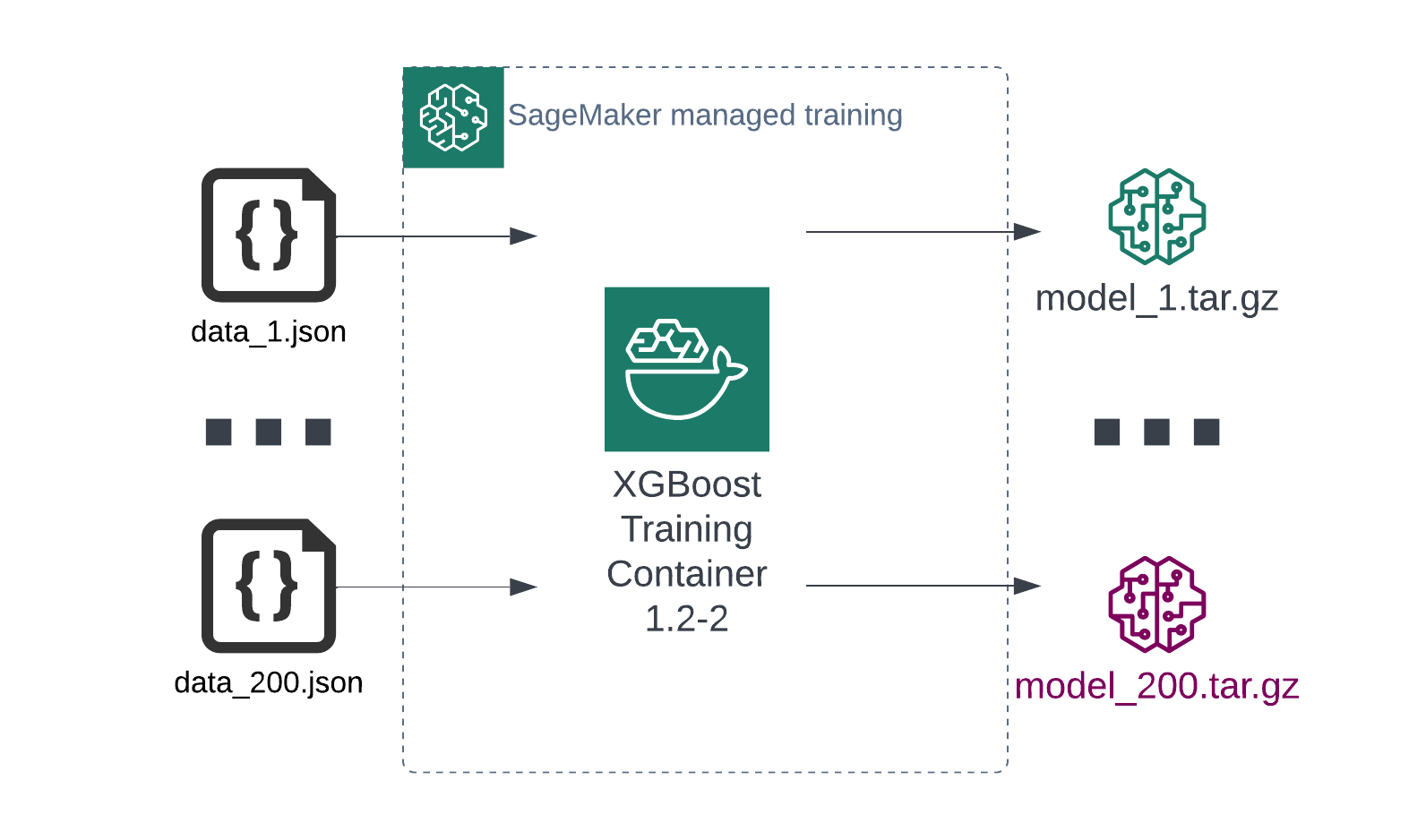
In this case, all you have to do is to run one batch transform job per tenant and specify which tenant uses which ML model. This will result in many smaller jobs on separate compute clusters, but the end result will be the same:
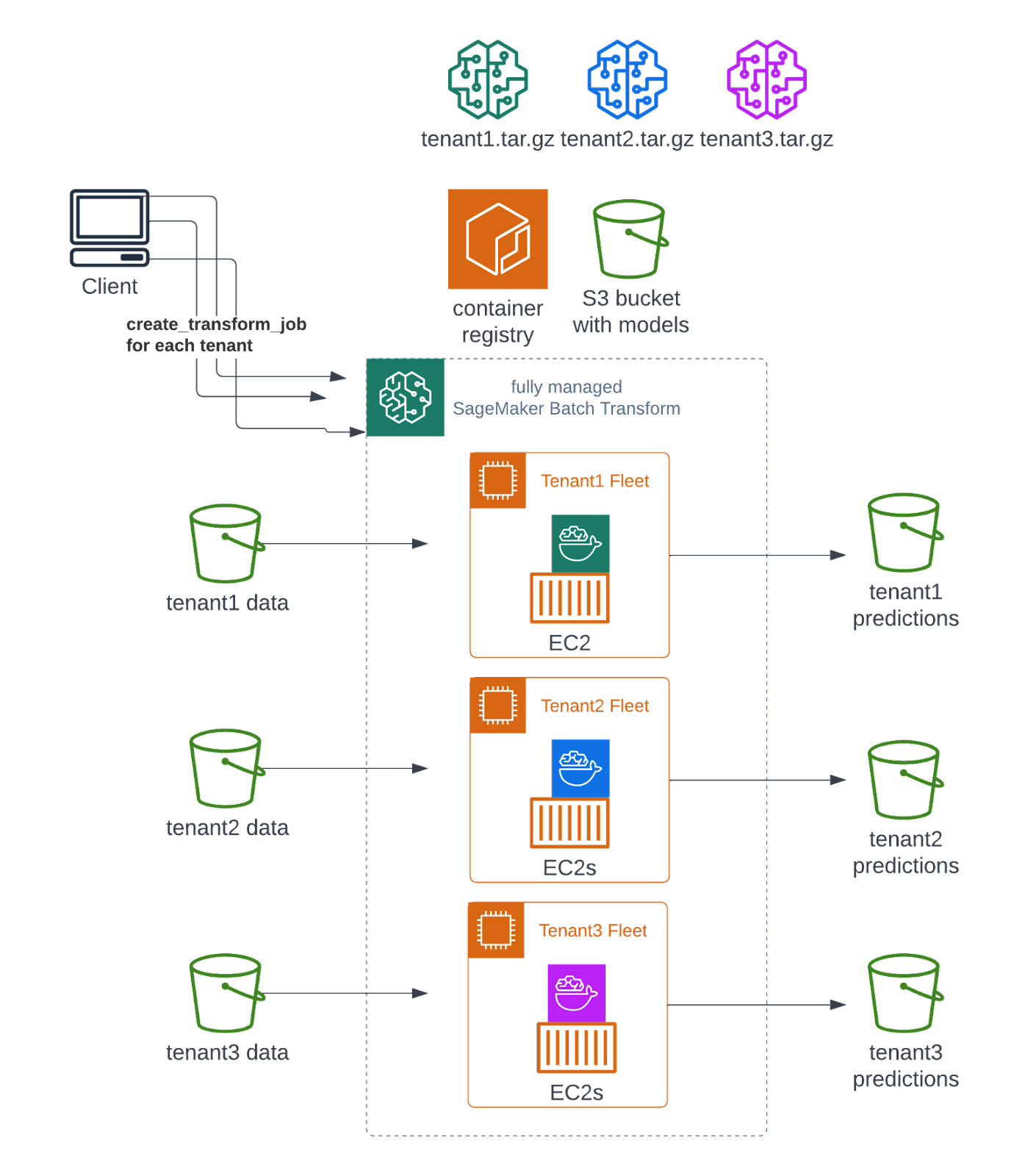
Batch transform requires little effort while delivering great results. Dynamically acquired compute resources with nearly unlimited capacity ensures that it scales with your business. And with no persistent clusters to maintain or shutdown, your data scientists can fully focus on the tasks that actually matter.
Real-time endpoints
Real-time endpoints work best in Silo, due to easy cost prediction and cost granularization. You need one endpoint and cluster per tenant. The quotas for this example are 6 MB payload size and 60s inference timeout. It is usually sufficient, but if you need more than that, an Asynchronous Endpoint may be the right one for you.
Batch transforms cover the offline, batch use case. However, some insights have to be delivered on a near real-time basis (think anomaly detection - you wouldn’t want to wait until next month to find that there was a fraud, you need an instant notification). In general, this is the most common ML deployment scenario. You need an always on, highly available endpoint running your model. And indeed, Amazon SageMaker Inference will provide you with one:
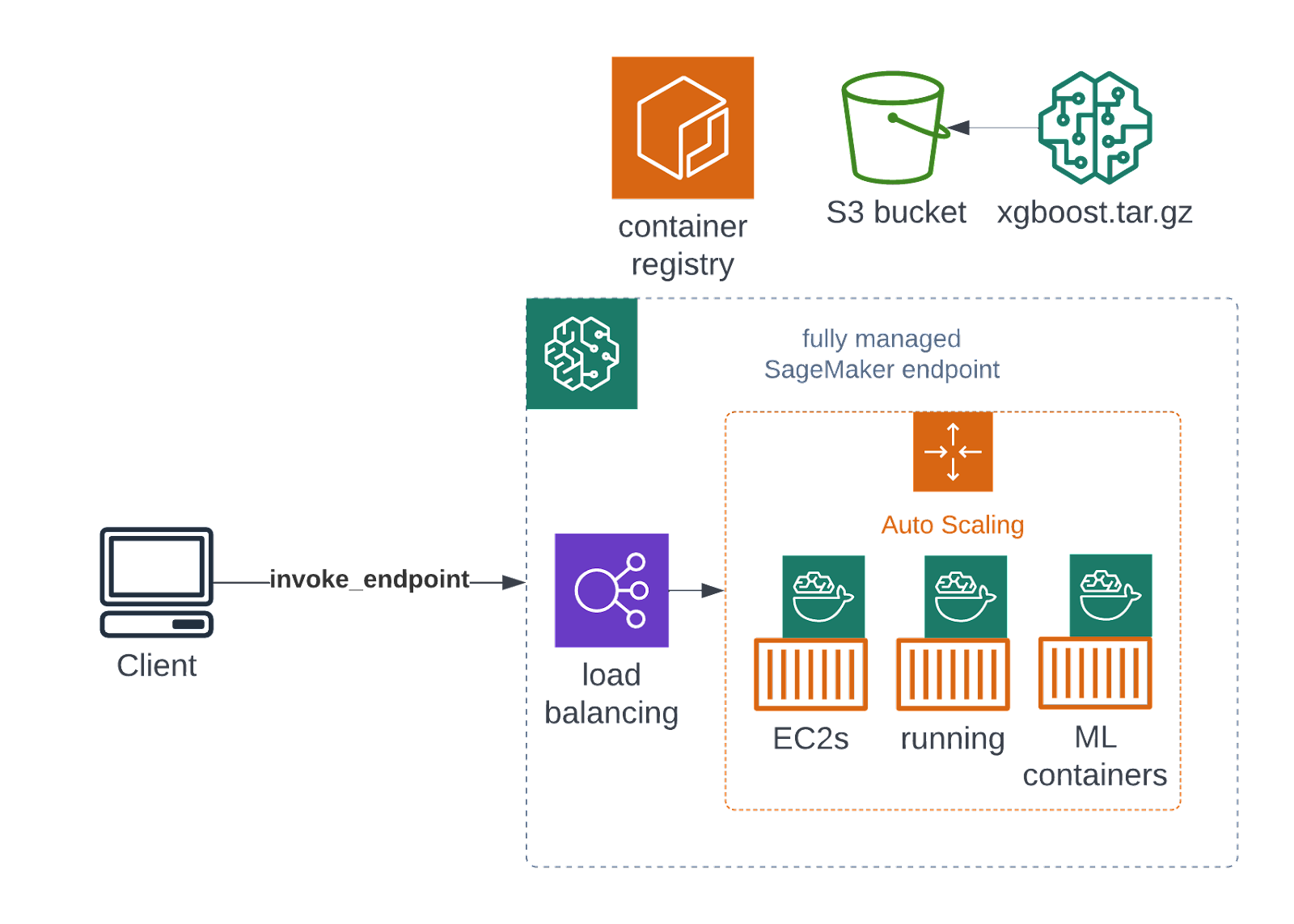
A highly-available endpoint can be used by your tenants, business intelligence applications and dashboards. You can easily add auto-scaling mechanisms to cope with rising loads if your SaaS becomes more popular.
Asynchronous endpoints
Asynchronous endpoints can be successfully used in Silo. In Bridge or Pool you still need a separate endpoint and compute resources for every tenant.
Instead of waiting for an instantaneous response, a client can upload their payload and schedule a job, then wait some time for it to finish. Due to Amazon Simple Notification Service native integration, they will be automatically notified in case of success or failure:
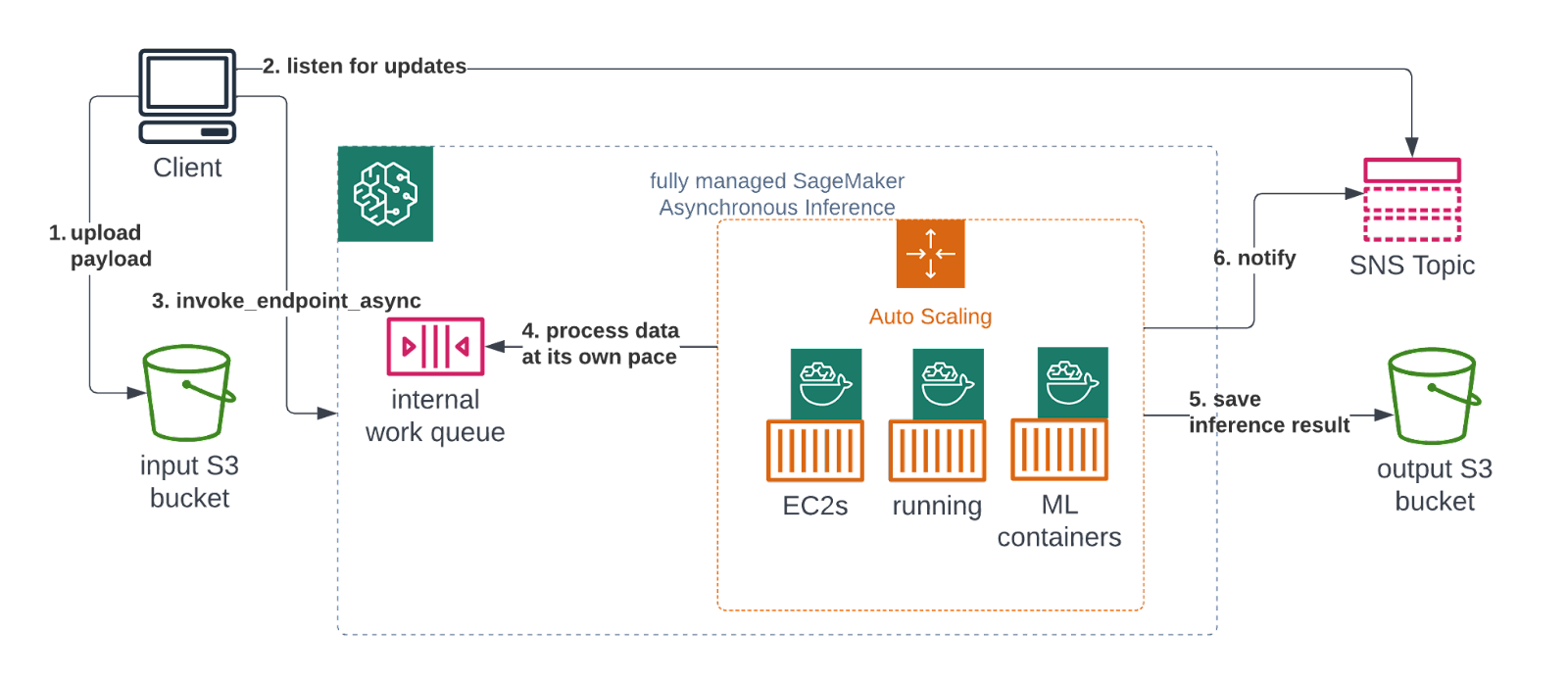
Obviously, the response time here is measured in minutes and not milliseconds. But this also has several benefits over the Real-time version. Firstly, the payload size limit rises significantly, up to 1GB. Secondly, the inference timeout is now 15 minutes, up from 1 minute. Both these improvements should cover most ML inference cases, even those in computer vision or natural language processing. Lastly, the endpoint can automatically scale to 0 machines in periods of low traffic.
Serverless endpoints
Serverless endpoints can be used in Silo only.
At the time of writing, a new inference type has become generally available. This type seems to be a very promising solution with potential for BI SaaS applications. Amazon SageMaker Serverless Inference replaces the always-on EC2 cluster behind your Real-time endpoint with a serverless AWS Lambda service.
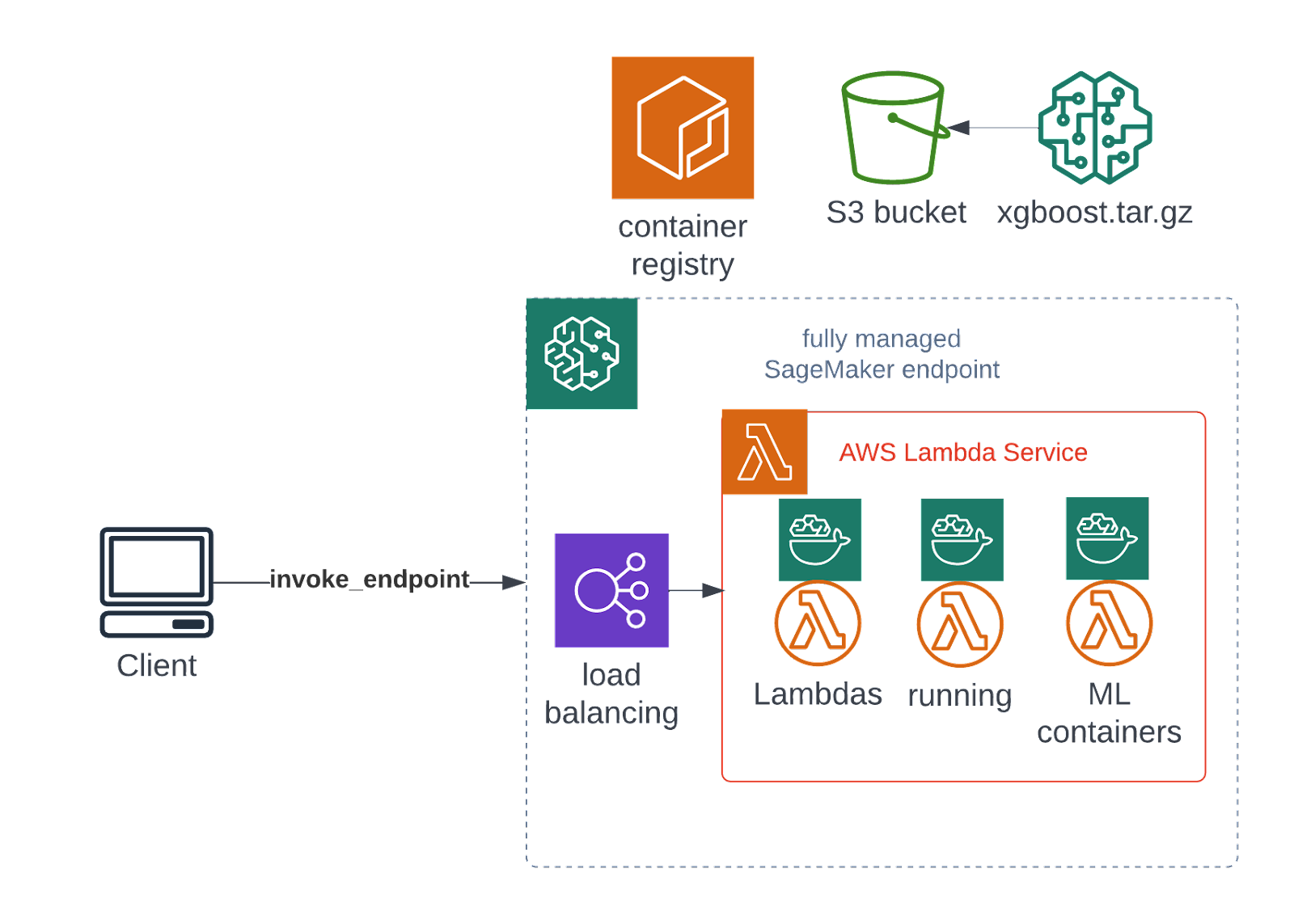
This is a crucial difference, because with serverless environments you only pay for the invocation time measured in milliseconds. There’s no always running (and always billing) endpoint with a cluster of machines, built-in autoscaling without any additional configuration, easily granularizable costs and no maintenance burden are all benefits of this type.
AWS will spin up a lightweight VM based on Firecracker technology, whenever a request is made, to perform the ML inference. That VM is also kept alive for a while in case more requests should come. If there are no requests for a prolonged time (around 5-10 minutes), that VM is turned off.
Additionally, each VM can only handle one request at once, so if more than one request comes concurrently, several VMs will be spawned. But, as we’ve mentioned - you don’t configure or maintain anything, this is all managed on AWS’ side automatically.
The downside of a serverless architecture is that some of your requests will inevitably be penalized with a higher latency due tocold starts. In machine learning problems utilizing large NLP or CV models, you often need to download and load GB-sized models into memory. This obviously takes time and might result in time (probably dozens of seconds) that some of your customers will have to wait before getting a response.
Techniques such as model pruning, quantization, knowledge distillation or just using a simpler algorithm may help with this problem. For now, you can not provision the concurrency either (i.e. have several VMs kept always alive) like you could do with AWS Lambda.
Multi-model endpoints
Multi-model endpoints can only be used in Bridge or Pool.
Both Real-time and Asynchronous versions expect a shared model between all your tenants - but, as with Batch Transform,you usually have a tenant specific machine learning model. Using the Real-time endpoint in Silo, would mean an uncountable amount of always-on separate endpoints. Think about the bills!
Asynchronous endpoints can scale to 0, which makes things better, but that is still a high maintenance burden if you count your tenants in the thousands. Serverless endpoints might lower the operational overhead further, but that still could mean hundreds of endpoints to manage. And it comes with the cost of all those cold starts too.
Therefore, Bridge is definitely more popular in these scenarios, due to a Multi-model feature of Amazon SageMaker Inference.
A machine or a cluster of machines will dynamically load and unload models on a request basis (TargetModel parameter in HTTP request). When a tenant’s dashboard or application requests for a model inference, the endpoint will first check its cache. If the tenant’s model is there, an instantaneous response is returned. Otherwise, the model is loaded from a predefined S3 bucket onto the machine and memory, and only then a response is given.
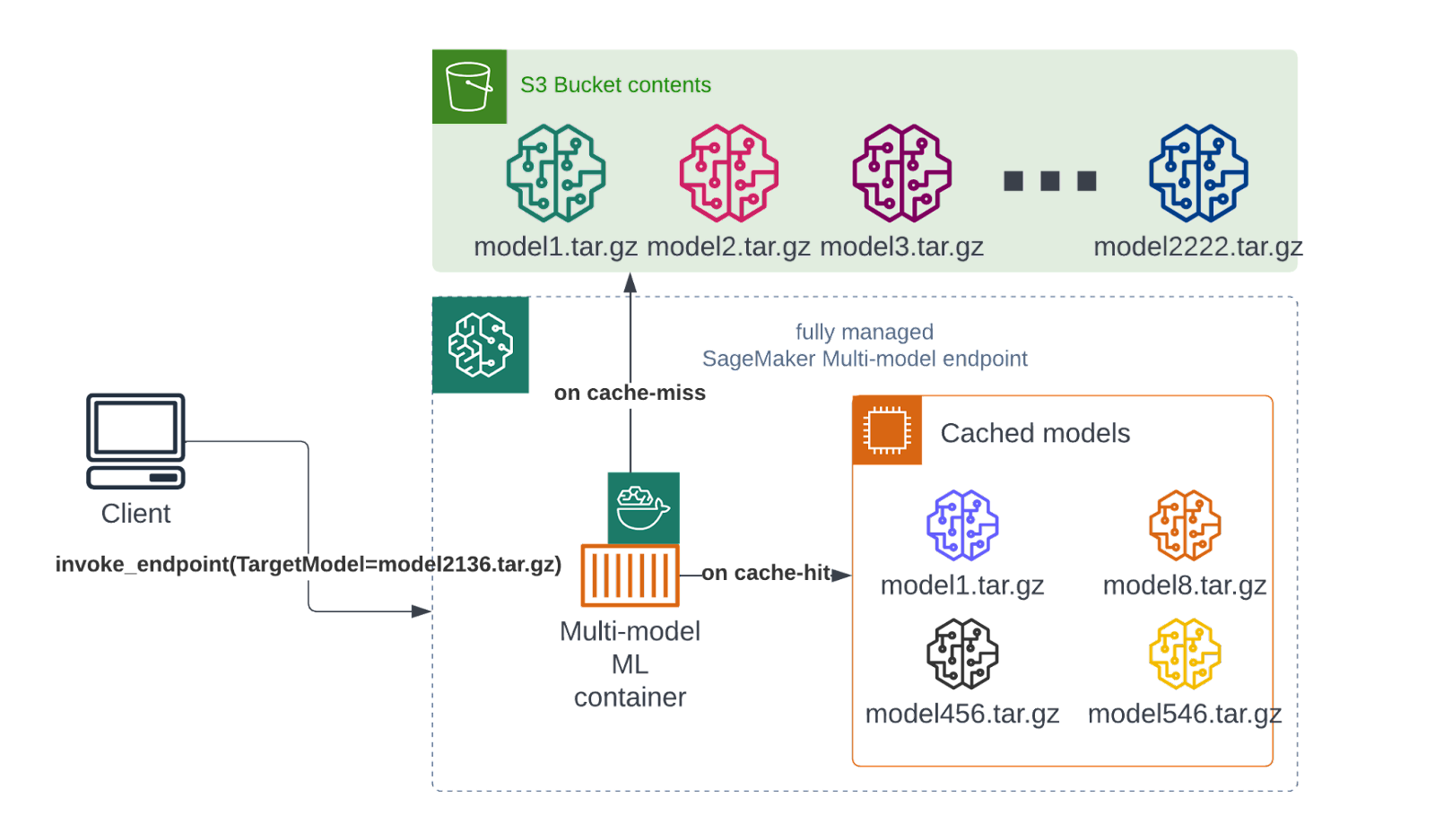
This allows you to lower your costs by an order of magnitude by sharing the machines between all tenants. Again, this comes with a tradeoff - if you miss the cache, you get a penalty in terms of a higher latency on a given request (this is also called a cold start). But, if the models aren’t too large, or your applications and visualizations don’t mind waiting a couple more seconds, this is a great solution.
Bear in mind that this also requires that the container used to train and serve the model is the same on every tenant. The image below has already been shown, but it is crucial to understand that mandatory requirement. Thus, a quick repetition:
You produce different models for different tenants, but the algorithm/container is the same for all of them.
Multi-container endpoints
Multi-container endpoints can only be used in Bridge or Pool.
What if your application does not meet reuse the same containers? What if each tenant has a different model produced by a different container? In such a situation, both datasets and training containers differ between the tenants:
Thankfully, you can still enjoy the cloud’s economy of scale and use a multi-container endpoint. This tweaks a real-time endpoint by making it deploy multiple (up to 15) containers onto the same EC2 machine.
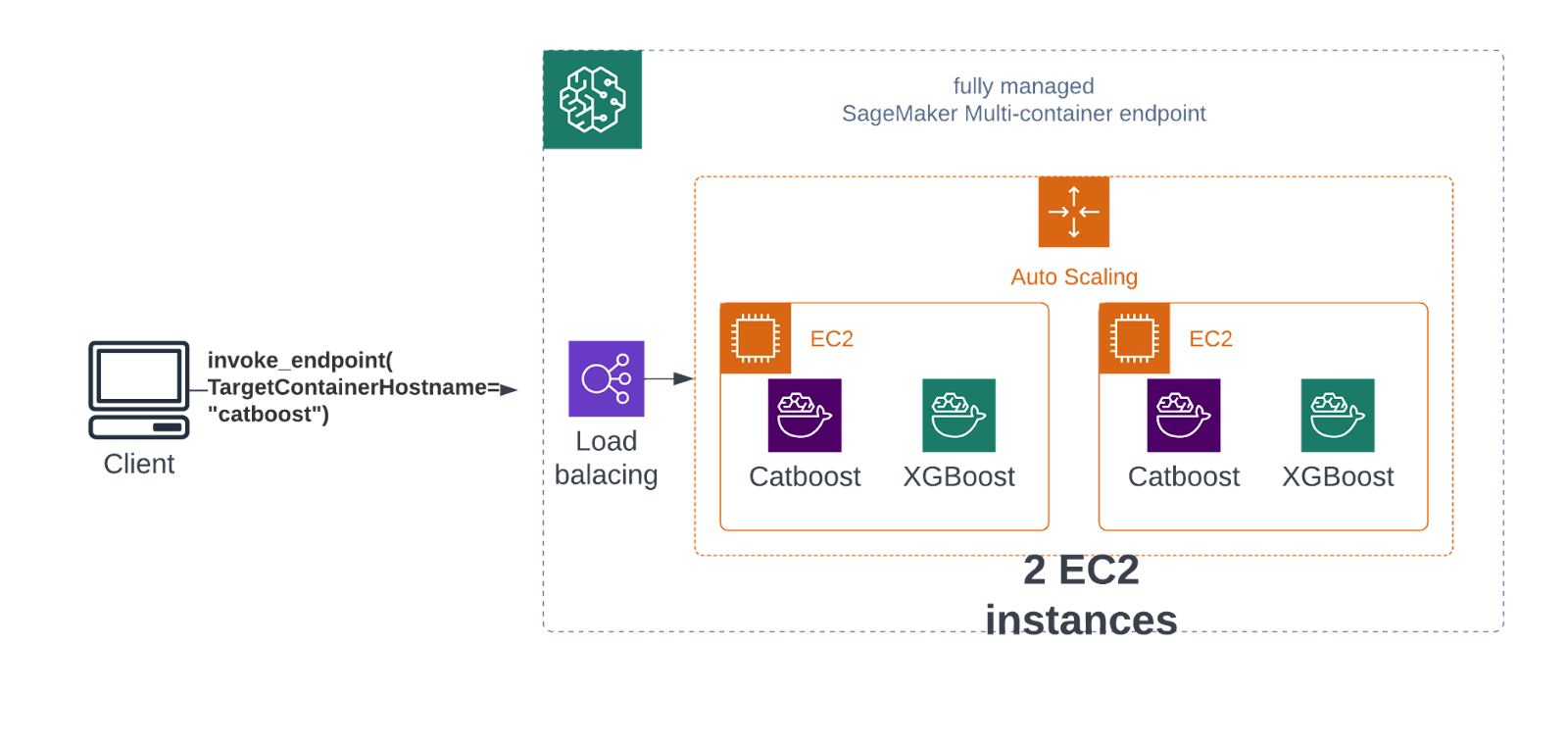
A client must specify the model they need by using the TargetContainerHostname parameter. And so, you can pack dozens of models onto the same machine and let them share resources. This can slash the overall cost by a factor of 15, while also making it way more manageable.
Summary
Amazon SageMaker Inference has evolved over the years to become the leading platform to deliver ML projects at any scale. Since it is not domain specific, Business Intelligence SaaS applications can benefit enormously from utilizing its diverse feature set.
If you need pre-generated, offline prediction mechanisms, Batch Transform is the way to go. In case of near real-time requirements, you usually go with Real-time, Serverless or Asynchronous endpoints, depending on your latency and payload needs.
What if you have hundreds of models to serve? Not an issue, just use a Multi-model endpoint.
What if each model is based on a different container? SageMaker also has you covered with Multi-container endpoints
Automation appendix
Now, for an appendix, automation time! The amount of toil and manual work in SaaS applications needed to onboard and successfully operate one tenant must be as low as possible. Since people are the most important part of every company, and it is time-consuming to acquire them, we need to let machines do as much work as possible for us. We don’t want to say “no” to our potential tenants, due to insufficient resources on our side.
We could write up another article about performing all (re)deployment operations around SageMaker Inference automatically, but there is a great one already present on AWS APN Blog. It concerns automating SaaS ML environments with SageMaker Pipelines. Make sure to read it as a complementary article.
…and don’t be shy to check out our review of Amazon SageMaker Pipelines as well as AWS Step Functions to pick the correct orchestrator for you.
