How to create your own Dropbox alternative in AWS
Exploring what's needed to build your personal Dropbox clone using Lambda and Amazon S3 for storage while keeping costs in check.
 Amazon S3
Amazon S3 AWS Lambda
AWS Lambda Amazon API Gateway
Amazon API Gateway AWS IAM
AWS IAM Amazon Cognito
Amazon Cognito

Full transparency of cloud storage bills is something I never got out of commercial solutions with fixed subscription packages. I mean, some files I store are better off in cold storage and my family will always drop and forget and remember it 6 months later. We can do better and account for that with some work.
I am briefly going to describe the architecture behind something which could be called a fully serverless object uploader, built on S3 Object storage, with some validation (in this case I have implemented a user upload cap but can be anything else) and — less obvious but also important — object listing.
Please note that this is merely an introduction to a PoC intended to explore whether it is possible to control how much an authenticated user can upload to S3, and where exactly.
Dive in
First, let’s aggregate some basic knowledge. We want to be able to impose upload limits early on so that we can keep total usage reasonable later on as our PoC progresses.
Since API requests to AWS (S3 in this case) are ultimately just HTTP under the hood, we can use the Content-Length HTTP header to check our request is not shooting over the upload cap:
TheContent-Lengthentity-header field indicates the size of the entity-body, in decimal number of octets, sent to the recipient or, in the case of the HEAD method, the size of the entity-body that would have been sent had the request been aGET. — w3.org/Protocols/rfc2616/rfc2616-sec14.html
Can we get S3 to validate the byte size of a request?
Amazon S3 POST policy conditions
Normally objects are PUT into S3. However, there is a lesser known feature in S3 that had been introduced primarily to enable browser-based uploads, and it happens to feature exactly what we need: POST policy conditions. Those allow us to e.g. check the minimum and maximum allowable size for the uploaded content.
An example POST policy condition to restrict exactly how large an uploaded object can be, could look like this:
{"Bucket": "bucketName","Fields": {"key": "user@email.me/objectName"},"Conditions": [["content-length-range", MIN_SIZE, MAX_SIZE]]}
With MIN_SIZE and MAX_SIZE replaced with our size boundaries, of course. The entire policy then needs to get gets attached to the formData used by browsers to upload objects directly to S3.
Later on, we should be able to generate these policies on the fly if a user’s usedStorage is less than their uploadCap.
The glue
So far so good, it’s just how fast can we glue this together so that we can start working on a client application.
Clearly we don’t want to give access to our serverless app to just anyone — AWS Cognito can cover our authentication and authorization needs. We periodically cover its features on our blog, but if you’re unfamiliar with the basics of AWS Cognito, we got you covered as well.
Our API is surely better off serverless given how rarely we are going to invoke either endpoint. Define your endpoints for GET /session and PUT /session within API Gateway to invoke your respective Lambdas.
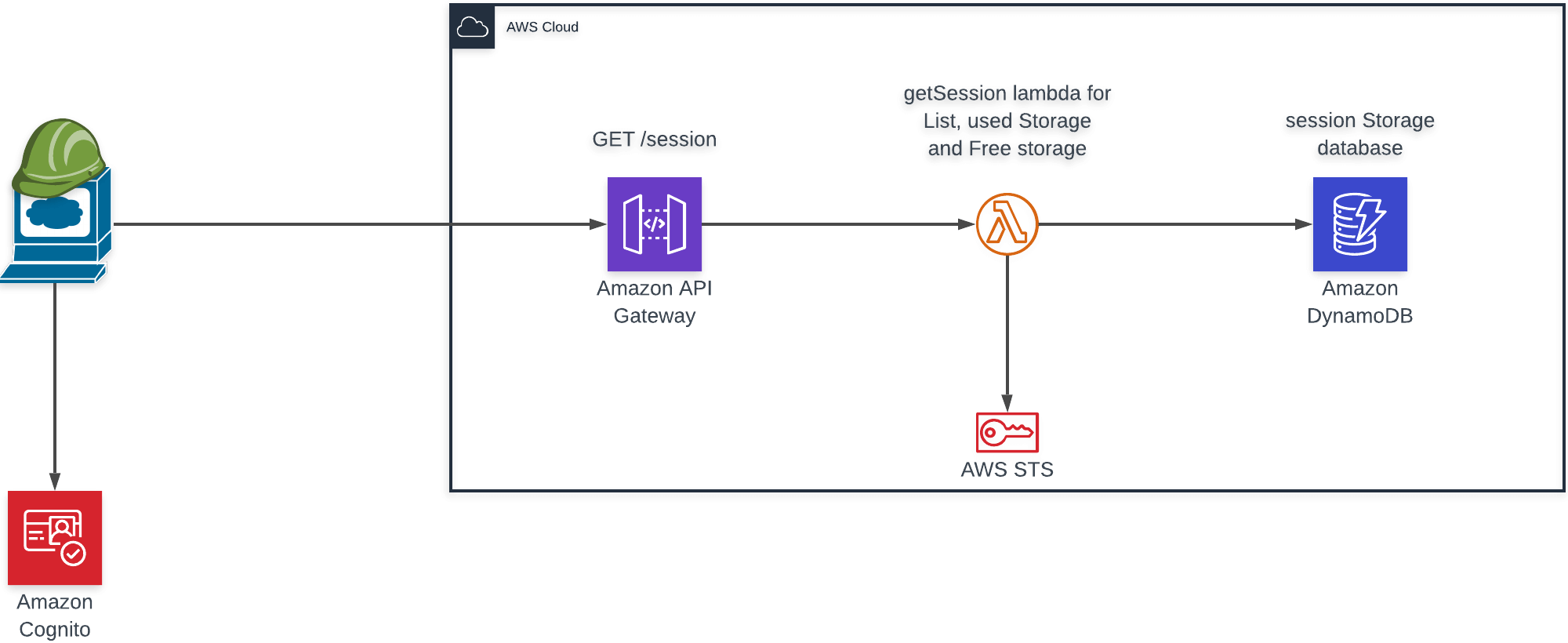
The request flow of a GET /session request responsible for retrieving data from storage.
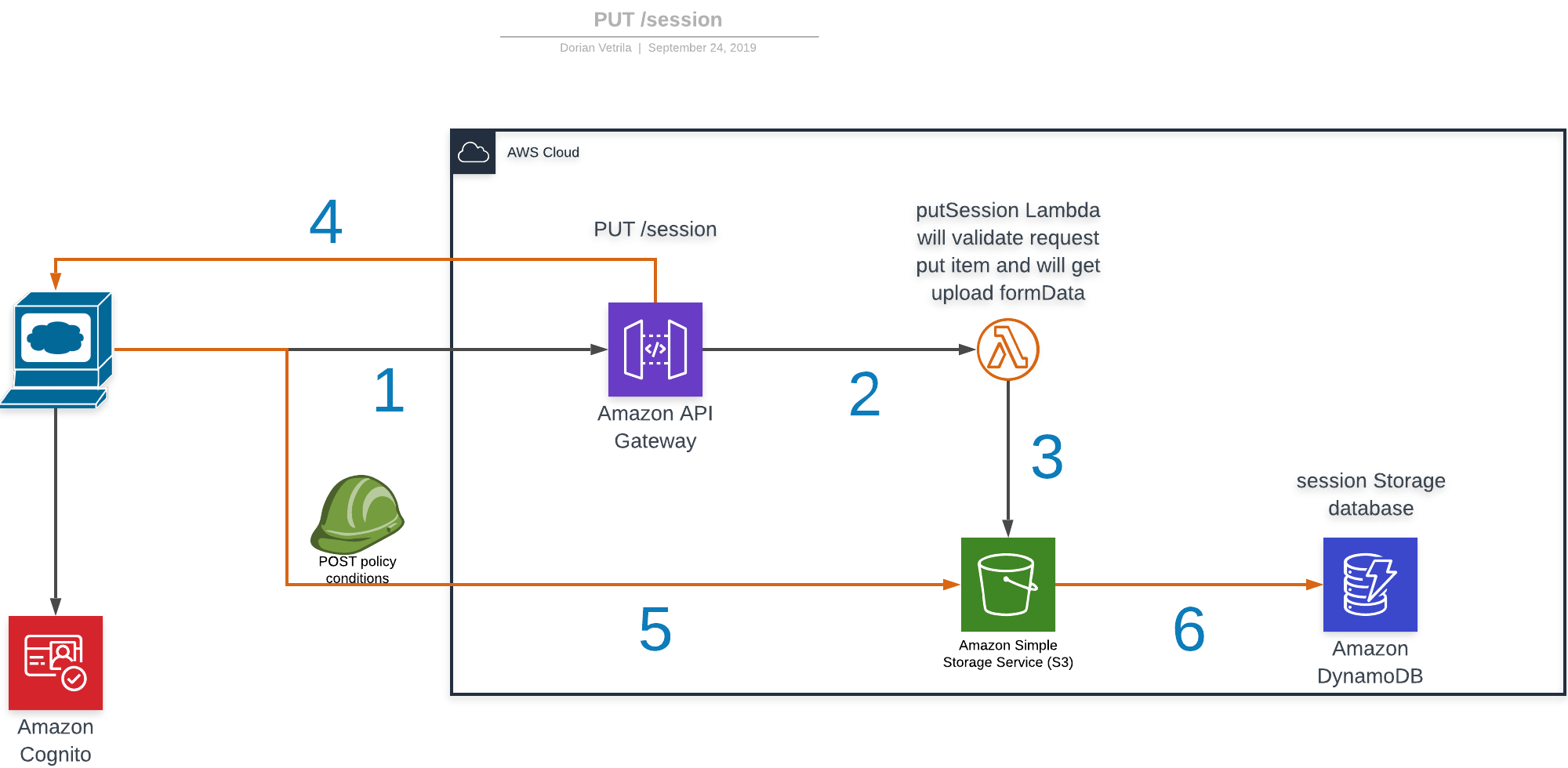
The request flow of a PUT /session request responsible for storing data parsed from valid requests.
While diagram 1 is a straight forward wrapper around IAM roles, in diagram 2 the flow makes more sense if you look from the perspective of DynamoDB which holds the state of your upload (INITIATED, REJECTED, COMPLETE) — using these flags made it easier to debug on the way and can we used in the future to backtrack issues with uploads, it doesn’t cost anything having here anyway.
While the first two (INITIATED, REJECTED) are easy to settle on per first upload request, the last (COMPLETE) one can be written as a result of the S3 trigger.
So in order of occurrence, on diagram 2 we have got the happy path:
- Request to API Gateway with the
Content-Lengthwe want to upload; - The content length is validated and a
POSTpolicy condition is created; - S3 creates
formDatafor the upload with thePOSTpolicy from step 2 and inserts item in DynamoDB withUNPROCESSEDflag; - Used storage + free storage +
formDatais returned to the client; - Send request directly to S3 with the upload request and delegate validation to AWS;
- An S3
object createdevent triggers a Lambda which changes swaps theUNPROCESSEDflag toCOMPLETEin our DynamoDB tracking table.
Cost and summary
This being completely designed for home use I estimated negligible Lambda and API Gateway requests, firmly staying in the free tier.
2 requests per upload, 1 per list and 1 per download = 4 requests per object max.
Give or take, for 1TB of pictures that’s 312500 objects.
- S3 Standard — Infrequent Access (S3 Standard-IA): $16.96 per month
- S3 Glacier — $4.6 per month
- S3 Standard — $25 per month
While this is somehow more expensive than some of the shelf commercial solutions, I know there will be other S3 API compatible solutions which will take this PoC to the next level.
This is nowhere near a finished solution. It will require more thought around upload state handling. Object namespaces — I would like to make use of object tags to avoid clashes. What about the lifecycle of objects? Glacier could give us great savings.
But this is a good start covering the serverless building blocks for our homebrew S3 alternative to Dropbox that I intend to continue expanding upon.
