Fargate and your first copy tool
Let's look deeper into AWS serverless services and try to make our S3 copy tool.
 AWS Fargate
AWS Fargate Amazon Elastic Container Service
Amazon Elastic Container Service Amazon S3
Amazon S3

Today, we are going to look deeper into AWS serverless services and try to make our S3 copy tool. What exactly do we want to create? Imagine that you have some objects stored in S3 bucket on account A, but, for some reason, you decided to copy all your objects to another S3 bucket. So, where’s the problem? Well, your second bucket needs to be created on account B. Let’s complicate things a bit more. Your second bucket will be in a different region. And to make it even more hardcore, we will use fargate to create it. Sounds difficult? Maybe a little, but with serverless we can achieve success. So, let’s get started!
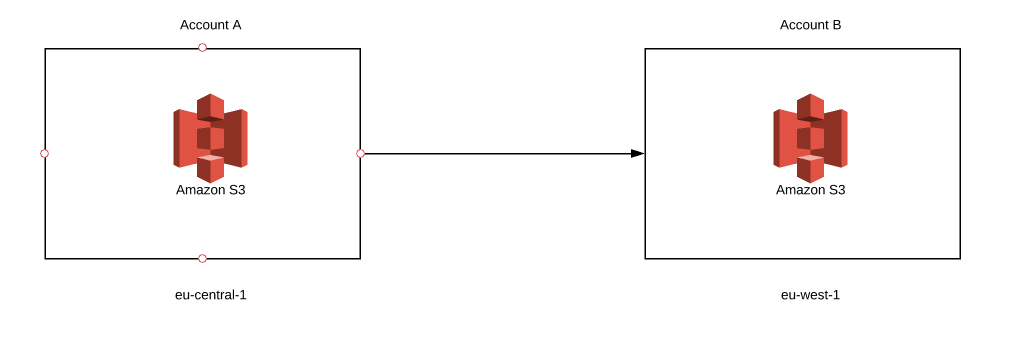
Why Fargate?
If you read my previous article, you should know about another serverless service called Lambda, which is also a tool we could use for our purposes. So, why are we not going to do it? Unfortunately, the copy process between two buckets can take a while. Depending on the amount of data, it can last seconds, hours, sometimes even days. Lambda’s execution limit set to 15 minutes is, without question, the main reason why we will avoid it in this case. Instead, we will focus on a container service. Once again, we have to consider two options - running it with EC2 or Fargate. So, why did I decide to use the latter? As it was mentioned before, it is serverless. To use EC2, we need to configure an extra server for running our container task. In short, we go to the EC2 page, select the proper instance type (which sometimes is not so easy), define some traffic rules and launch it. Now, what problems can this cause? If we select an instance that’s too small for our task, it will suffer from lack of memory. If we choose one that’s too big, we will pay extra money for unused capacity. The next problem is managing EC2 after launch, because pathing, updating or dealing with secure issues becomes your responsibility. As a result, you waste a lot of time managing and operating your EC2 instance. With fargate service, we only pay for what our task uses during execution. What’s more, all underlying infrastructure is managed by AWS. So, instead of focusing on your environment you can concentrate on developing your application. Quite a useful option, don’t you think? I hope the discussion about using fargate is behind us, and we can move to something more interesting, like building our application.
Prerequisites
First of all, you need to create 3 roles.
- Gives access to source bucket on account A
- Gives access to destination bucket on account B
- ECS service role that allows to assume roles
First two roles are obvious, but why do we need the third one? When we use Fargate service, we can’t assume other roles without permission and we can’t put two roles inside one container. That’s why we have to create an extra one that enables us access to both.
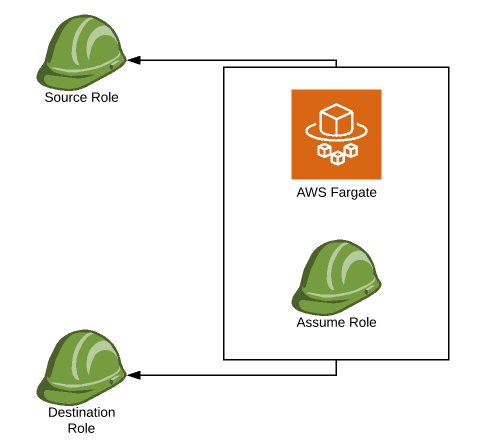
[!IMPORTANT] When we assume a role inside our code, we always have to use a container role. If we assume a source role, and then try to assume a destination role using source credentials, it will fail due to missing assume role permissions. If we want to get credentials from first and second role simultaneously, we have to start with creating sessions of container role.
ses = boto3.session.Session()Now, we can assume both roles (it can also help with refreshing tokens - I will describe it in the next article).
sts_client = ses.client('sts')assumedRoleObject = sts_client.assume_role(RoleArn=sourceArnRole,RoleSessionName=sourceRoleName)source_credentials = assumedRoleObject['Credentials']assumedRoleObject = sts_client.assume_role(RoleArn=destinationArnRole,RoleSessionName=destinationRoleName)destination_credentials = assumedRoleObject['Credentials']
Once we retrieve credentials from both roles, we are ready to create our s3 clients/resources.
sourceResource = boto3.resource('s3',aws_access_key_id=source_credentials['AccessKeyId'],aws_secret_access_key=source_credentials['SecretAccessKey'],aws_session_token=source_credentials['SessionToken'])sourceClient = boto3.client('s3',aws_access_key_id=source_credentials['AccessKeyId'],aws_secret_access_key=source_credentials['SecretAccessKey'],aws_session_token=source_credentials['SessionToken'])
Above objects give access to the source bucket and its content. We can use destinations_credentials in the same way to get access to the destination bucket.
There is one more step we need to take in order to make our app work. We have an object that gives access to the source bucket and another one that gives access to the destination bucket, but it’s impossible to use them both in the copying process.
destinationClient.copy_object(Bucket=destinationBucketName,CopySource=sourceBucketName,Key=key_name)
We need to enrich our source bucket with policy that enables access using destination credentials.
json_str = destinationClientSts.get_caller_identity()dstNumber = json_str[u'Account']
First, we will get an account number of a destination bucket. It will be needed in our policy.
You need to create sts client by using destination assume role credential. When you create boto3 clients, using S3 service, create one more with sts.
bucket_policy = {"Version": "2012-10-17","Statement": [{"Sid": "Destination permissions","Effect": "Allow","Principal": {"AWS": "arn:aws:iam::" + str(dstNumber) + ":root"},"Action": "s3:*","Resource": ["arn:aws:s3:::" + bucket_name,"arn:aws:s3:::" + bucket_name + "/*"]}]}
That’s a policy which allows us to access the bucket with destination permissions. I hope you read my previous articles, but I will explain the resource part in case you didn’t.
"arn:aws:s3:::" + bucket_name— gives access to items directly inside s3 bucket"arn:aws:s3:::" + bucket_name + "/*"— gives access to folders and subfolders inside s3 bucket
Finally, we can put our policy into source bucket:
bucket_policy = json.dumps(bucket_policy)sourceClient.put_bucket_policy(Bucket=sourceBucketName, Policy=bucket_policy)
At last, we can forget about the source client/resource object and from now on use only destinations.
Copy objects
When it comes to copying s3 objects, there are two possible scenarios we need to consider. Use an already created bucket or create a new one. To make it more interesting, we will try to create a bucket.
destinationClient.create_bucket(Bucket=bucket_name)[!IMPORTANT] Create a unique name for your bucket as the namespace of buckets is global. There is no way to create two identical bucket names (even on different accounts) and the fact that all S3 buckets share a public, global namespace has considerable security implications as well.
That’s the simplest way to create a bucket. But in which region the bucket will be created? The answer is simple, in the region where fargate and your containers are created. We didn’t include the region name in any previous steps, so the region will be taken as default. To create bucket in different region, we need to do two things:
- Create a client in a given region:
destinationResource = boto3.resource('s3',aws_access_key_id=source_credentials['AccessKeyId'],aws_secret_access_key=source_credentials['SecretAccessKey'],aws_session_token=source_credentials['SessionToken']region_name = region)
You can swap region with any valid AWS region, like eu-west-1, eu-central-1, us-east-2 etc.
- Constrain the bucket to the given region during creation:
s3.dstclient.create_bucket(Bucket=bucket_name,CreateBucketConfiguration={'LocationConstraint': region})
[!IMPORTANT] You can put any valid region in place of region, but the client's region and the bucket's region must be the same. Differences between those values will cause IllegalLocationConstraintException.
us-east-1 is the default region and does not need to be specified during bucket creation. However, our client would still need to be scoped to this region regardless.
The copy process itself is quite simple. We need to retrieve all bucket keys and then copy them all with the copy_object function:
for key_name in keys:destinationClient.copy_object(Bucket=destinationBucketName,CopySource=sourceBucketName,Key=key_name)
[!IMPORTANT] Remember to use the destination client when copying objects.
We enriched the source bucket so it could be accessed with destination credentials. As a result, using source credentials will cause access denied to destination bucket, because its policy will be set to default values.
That’s all, you have your working app copy which can be launched on Fargate. Now, let’s explain how we can run it.
Application image
I recommend you read my previous article where I’ve thoroughly described what happens during each step of creating/deploying your image. Here, I will do it very briefly. So, let’s create your image.
FROM python:alpine3.6COPY . ~/Desktop/python_image/imageWORKDIR ~/Desktop/python_image/imageRUN pip install -r requirements.txtCMD python ./migrator.py
[!IMPORTANT] migrator.py is the name of my entry module — change it to your own module’s name.
Here’s your Docker file that will create your image. To build it, just run the following in your terminal:
sudo docker build .If everything went well, you should get your image ID which will be used to put your image inside ECR.
- Get your ECR login credentials:
aws ecr get-login –no-include-email –region eu-west-1- Log to your ECR service using the password retrieved in the previous step. Just replace the
****after-p:
docker login -u AWS -p **** https://****.ecr.eu-west-1.amazonaws.com- Tag your image:
sudo docker tag **** s3-copy-repo:latest- Link your image with your ECR repository:
sudo docker tag s3-migrator-repo:latest ****.ecr.eu-west-1.amazonaws.com/s3-copy-repo:latest- And finally, push your image to the ECR repository:
sudo docker push ****.ecr.eu-west-1.amazonaws.com/s3-copy-repo:latestFargate and container
Log into your AWS management console and open ECS service. Then, click on Clusters -> Create Cluster. Choose Networking only and hit next. Enter example name or optional tags, if needed, and hit create.
Back in ECS window, hit Task Definitions -> Create New Task Definition, choose fargate and hit next. Enter a task name and choose the container role which was created in Prerequisites sections. This is a role that makes assuming a role inside a container available.
Task size depends on complexity and performance you want to achieve. I suggest starting with the lowest number and make it higher if the task fails due to memory exception, or if the performance of the running task is extremely low.
In the container section, create a container with the path to the image (pattern is given).
Add optional tags if you will, and hit create. Now, you should be able to run your fargate task and start the copying process.
Lambda and how to run my task
You can use AWS Management Console to run tasks, but since we’re exploring a serverless approach in this article, we will use Lambda. The code that will help us do that can look like this:
def run_task(data):client = boto3.client('ecs')response = client.run_task(cluster='cluster_name',launchType = 'FARGATE',taskDefinition='taskName:version',count = 1,platformVersion='LATEST',networkConfiguration={'awsvpcConfiguration': {'subnets': ['subnet-*******'],'assignPublicIp': 'ENABLED'}},overrides={'containerOverrides': [{'name': 'containerName','environment': [{'name': 'parameter1','value': 'parameter1_value'},{'name': ''prameter2','value': 'prameter2_value'}]}]})
[!IMPORTANT] Before running a task you need to give Lambda access to ECS.
Within our boto3.run_task() call:
cluster— put your cluster name herelaunchType— we use fargate so the value should befargatetaskDefinition— your task name and versioncount— number of tasks which will start every time you use this functionplatformVersion— uselatestnetworkConfiguration— here you need to put your vpc subnet which will be used to run tasks. The safest way is to putenablehereoverrides— here, you declare the parameter which will be passed to your task. In the environment section you can pass your parameters as a list of dicts. Name will be used later to get value viaos.environ
Now, you can run your Lambda and watch how your copy task starts. You can watch your task logs using cloud watch or inside the cluster. You can simultaneously run as many tasks as you want.
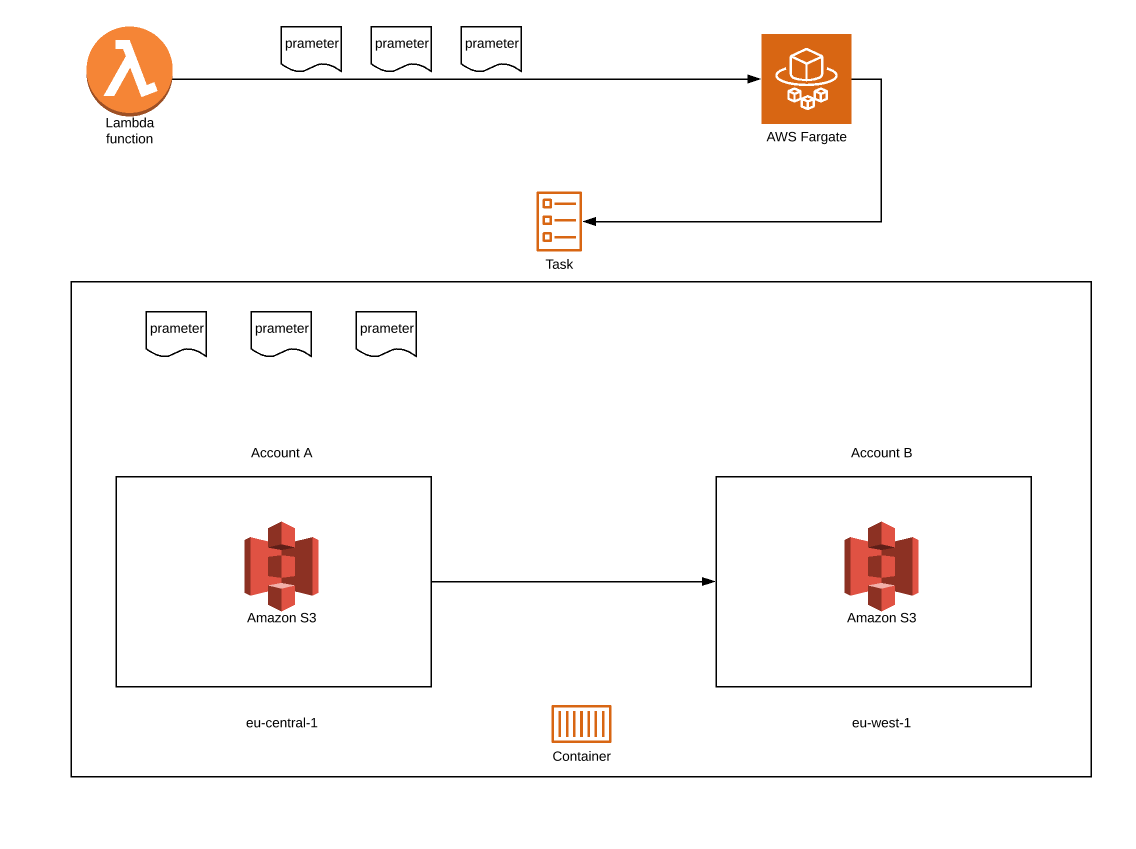
And that’s all?
For now, at least. We’ve created our first copy tool, but it is not the end. With fargate power we can expand functionality of our tool and prepare some new scenarios and features. You will learn more about image security from our next articles. You’ll also learn how to copy your object’s ACL, how to migrate your buckets, and how to refresh a role token if the process of copying takes more than a while. Plus, everything about using fargate. I hope you’ve managed to reach the end. I am really looking forward to solving new issues with fargate. If you are too, wait for the next part. See you soon!
