Amazon SageMaker Pipelines — MLOps on AWS
Learn when to use Amazon SageMaker Pipelines, and when to avoid them. Part of a series exploring MLOps services on AWS.
 Amazon SageMaker
Amazon SageMaker AWS Step Functions
AWS Step Functions AWS CodePipeline
AWS CodePipeline

People coming to the MLOps space and looking to automate their data science solutions might quickly get lost on the way, as AWS offers (at least!) three distinct serverless orchestrators — Amazon SageMaker Pipelines, AWS Step Functions and AWS CodePipeline. For historical reasons AWS uses all of them in their examples and Solutions Library, which does not help with strategic decisions.
The point of this series is to outline their main characteristics and use cases, show the crucial differences between them and help you decide which ones are right for you. They also play quite different roles in the MLOps area and understanding which-pipeline-is-responsible-for-what is vital. Initial pick may seem innocent, but as the project grows and the team gets to know the chosen tool, it might be too late to make a switch. If said tool wasn’t chosen wisely, it may cause a lot of headaches (and unnecessary coding!).
We will walk you through the basics of orchestration within the MLOps space and introduce Amazon SageMaker. If you already know the drill, feel free to skip right to the chapter “What is a SageMaker Project?”.
What is MLOps and orchestration anyway? Why would I orchestrate anything?
Data science projects never follow the usual software development lifecycle. In many prediction and forecasting tasks, we can hardly guarantee the end result, like we would in “classical” software development. You can specify how your web app or mobile app will look and behave, but you often cannot be certain how well your data science algorithm will predict the truth and if it will even output anything meaningful.
Instead of building a kanban board full of polished tasks, research phases are conducted, with an agile-ish milestone system. Each iteration should either improve the current result or give us more insights to work with (one of them might be “cancel the project altogether” or “can we tweak the requirements a little”).

The six phases of a typical machine learning lifecycle
A more thorough description of the entire process can be found in the Machine Learning Lens of the AWS Well-Architected Framework.
Most data scientists’ time is thus consumed by constant gathering of business requirements, understanding the business and wrangling the data from various sources together. What is left of it is spent on model building and debugging, although this is often a tiny percent of overall work. Resulting code is rarely production-grade as data scientists are usually more interested in bumping the model’s performance than refactoring their work to apply software engineering practices (and that is perfectly fine).
That said, if our end result is good enough — i.e. we finally fulfilled the requirements, know what data we need and which algorithm to train — we need to deploy our solution. However, this often requires a vastly different skill set than the one that a data scientist possesses.
This gave birth to the MLOps movement and jobs such as MLOps engineer or machine learning engineer. Shortly speaking, their job is first to make data scientists’ code more stable, robust, maintainable and debuggable and then deploy it somewhere with easy access to compute power with monitoring set up properly. Lastly, the entire process should be automated, reproducible and observable.
If you’d like to read more, I partially described it in my article “But what is this Machine Learning Engineer actually doing” a while ago. Nowadays machine learning engineers also spin up all the cloud infrastructure required, since machine learning platforms such as Amazon SageMaker matured into approachable and tamable ecosystems.
Even though the research phase is complicated and constantly shifts, if we finally get a well-performing algorithm, the steps to create it again can be written down in a detailed manner. Most of the time we will need to recreate (retrain) it many times. We want to feed the algorithm with fresh data points, for example customers’ behavior in a given week, to ensure it takes them into account when making new forecasts. Additionally, when a data scientist has a new idea and wants to create a quick experiment, a slight tweak in the algorithm shouldn’t require days of manual toil from them. The manual work is error-prone and mistakes such as “wrong file as an input” might not be immediately recognized and result in hours of debugging a model performance degradation.
These required steps form a workflow: a pipeline of well-defined actions that need to take place, should we wish for a fresh version of the algorithm. We need specialized software to operate it — a workflow management platform or an orchestrator if you will — and to take the burden of managing the execution of each step off our shoulders.
Some of the steps will require a large compute power, others will be merely one line of code or a tiny boolean check. We often need to run the pipeline on a schedule or automatically trigger when new data arrives. Errors should be either retried or handled. A friendly GUI to observe each execution, debug the issues and browse logs would be a huge plus. Additionally, we want to define what needs to happen and in what order — not code how it should happen. That means, the more infrastructure as code constructs and native integrations with various AWS services the better. Lastly, the less we need to manage the orchestrator itself, the more effort and resources we can spend on optimizing the algorithm. Serverless model shines here, as data science teams are not necessarily huge. We would rather hire one more data scientist to enhance the model, than spend that on a devops engineer operating the platform.
One of the most widely used such tools in the industry is probably Apache Airflow, also available on AWS as Amazon Managed Workflows for Apache Airflow (MWAA) since 2020. However, that service is only managed by AWS and is not serverless, thus out of scope of our serverless series. We will briefly mention it again though, in the last article of our series when comparing all solutions, as ultimately only Airflow provides some features you might require. Similarly, in Kubernetes-heavy environments advanced tools such as Argo or Kubeflow can be used, but they are also not fully serverless.
The subject of our article, the newest cool kid on the block is Amazon SageMaker Pipelines. As of recent additions to it, the service meets almost all criteria mentioned above. But first, we need a very brief introduction to AWS’ machine learning service, namely Amazon SageMaker.
Amazon SageMaker and its ecosystem
The most popular IDE of (Python-based) data science is Jupyter and its notebooks. “The REPL on steroids” enables you to run code line by line (or cell by cell), while not losing the context of previous executions. You can quickly test your ideas, visualise your data, see how your code behaves and even add some Markdown or LaTeX documentation in between cells with code. This is a really convenient way to program, not only for data science purposes. I strongly encourage you to give it a shot one day.
SageMaker was born 4 years ago as a hosted Jupyter service. With a few clicks your notebook could run on a powerful, external machine. Apart from managed Jupyter, it also provided capability to run your training and data processing scripts on AWS machines and save the results to S3. Lastly, you could deploy your model, i.e. spin up a container with it (and an API to access it) in an auto-scaling and highly available manner.
And this was only the beginning.
SageMaker evolved rapidly, into dozens of services forming nearly a separate cloud designed for machine learning purposes.
AWS re:Invent 2018 added a service that assisted with labelling your data or a “compiler” which optimized your model for your production hardware.
2019 brought us SageMaker Studio, their own “plugin” built on top of Jupyter to enhance data scientists collaboration (which also integrates natively with most SageMaker technologies), Experiments which help in organising your research and saving its results, Autopilot which is an AutoML service, Debugger or Model Monitor.
Last re:Invent 2020 expanded their offer even more drastically. They added Feature Store to share and reuse “insights” about your data, Model Registry to store trained models, Data Wrangler to easily perform a scalable data preprocessing or Clarify to explain model’s behavior and predictions.
Bear in mind we only mentioned some of the SageMaker technologies!
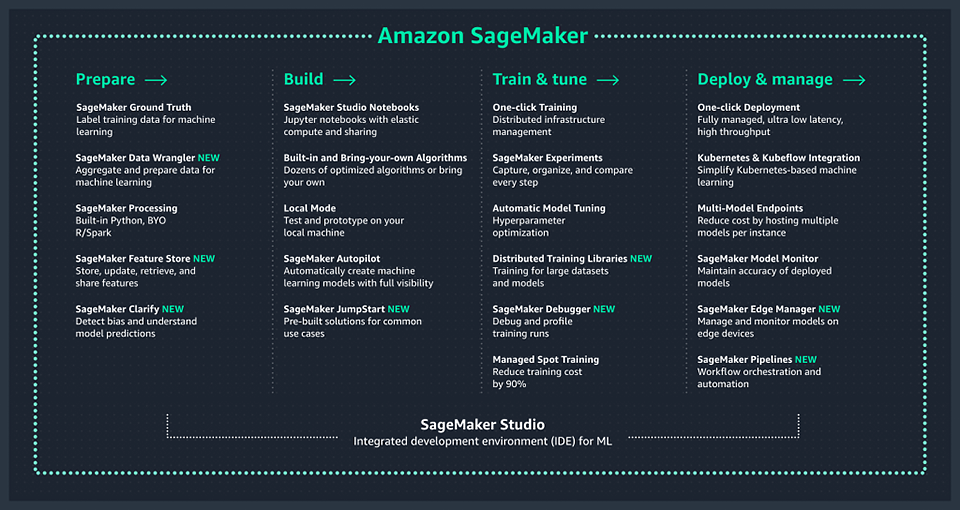
Services and tools available within the Amazon SageMaker suite at the time of writing
It truly is a fully-fledged ecosystem for machine learning. It is also clear that AWS closely follows or maybe partially leads current AI trends with their offerings, like for example XAI (explainable artificial intelligence — which is what SageMaker Clarify does). Observability, explainability, and reproducibility is already in AWS.
What is a SageMaker Project?
Prior to introducing Pipelines, we should also mention the existence of yet another SageMaker service. Since the MLOps space is pretty new, every company has their own, opinionated way to build and maintain machine learning systems at production. And so does AWS.
AWS’ approach to a MLOps management platform is SageMaker Projects. It aggregates various SageMaker offerings — Repository, Pipelines, Experiments, Model Registry and Endpoints — in one place. These form a dashboard containing all you’d need to know about the state of a given machine learning project. You are able to browse the code and the orchestration pipeline runs, see the models’ metrics and compare various experiments plus you can answer all sorts of questions like “which model is deployed where” or “what is the configuration of the deployment machines” — all that in one place.
If you ever used Neptune, MLflow or Weights & Biases, this is the same idea. In terms of AWS technologies that are also aggregates, AWS Amplify comes to mind (designed to rapidly develop web and mobile applications).
To make SageMaker Projects work, they do two main things under the hood: first, prebuilt templates are used (via AWS Service Catalog) which spin up considerable amounts of other AWS services for you. I mean, just look at this toy example which is set up for you as one of the SageMaker Projects Templates:
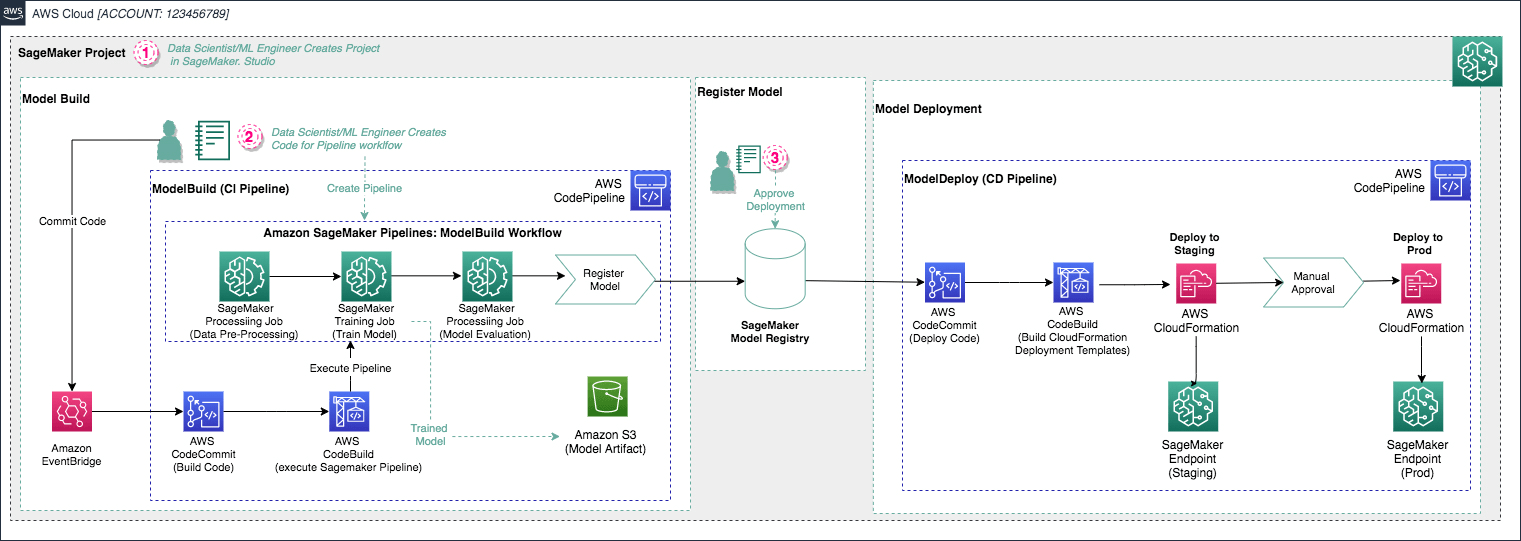
One of the prebuilt SageMaker Projects Templates available on AWS
Second, in literally every place possible (when interacting with SageMaker and other AWS services) they send the ID and name of the current SageMaker Project. This way you are able to view all entities associated with a given project (datasets, pipeline runs, experiments, endpoints). You may read more about how it works here.
The reason we mentioned it is simple — Pipelines are an integral part of Projects and most examples you find automatically assume you are using both. However, nothing stops you from using Pipelines without Projects. Their Templates just set up a very convenient way to work with machine learning projects in general.
I have since written another article focused on using SageMaker Projects to scale Amazon SageMaker for multiple teams that you might find interesting if you’re thinking about the proper organization of MLOps across an organization.
The basics of a SageMaker Pipeline
SageMaker Pipelines, available since re:Invent 2020, is the newest workflow management tool in AWS. It was created to aid your data scientists in automating repetitive tasks inside SageMaker.
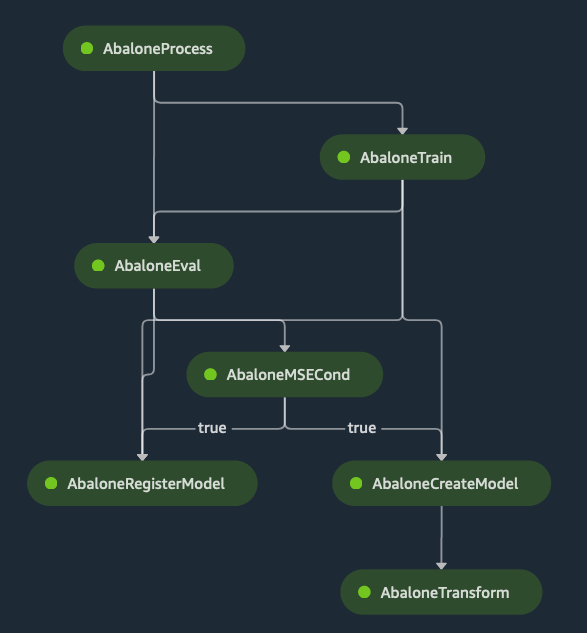
An example Amazon SageMaker Pipeline
As always when using SageMaker, the preferred way of interacting with the service is by using SageMaker SDK. Pipelines reside in the workflow module. All you have to do is wire objects you created using other SageMaker modules (like sklearn.preprocessing, estimator, processing or others). That means you must wrap them into Step constructs to define mutual dependencies. Optionally, you can also parametrize the pipeline (for example if you wish to easily change the machine type, stopping criteria or learning rate between executions) or set up step caching.
AWS Documentation creates the pipeline above as a toy example. Do notice how they interact with various SageMaker services. First they create a SageMaker resource like estimator.Estimator and then they wrap that inside workflow.steps.TrainingStep, which is Pipelines’ construct. It is likely your data scientists were already creating the first one - all they have to do now is to learn what the tiny Step wrapper does. That way you can spin up parametrized Processing Jobs, Training Jobs, Hyperparameter Tuning Jobs and Batch Transform Jobs using SageMaker Pipelines.
With a special Condition Step you can create a branch in your DAG depending on logical evaluation. A PropertyFile allows you to dive deep into JSON files (using JsonPath) to pick up the values for Condition Step. For example your Processing Job creates a summary of a model’s metric and saves them in a JSON file. You can then conveniently read its contents and proceed left or right in the graph, depending on the model’s performance. As soon as you define all the steps, you create a workflow.pipeline.Pipeline object to sum it all up and “save the pipeline definition” to AWS. Additionally, few additional capabilities are present.
By default, SageMaker Experiments are integrated with SageMaker Pipelines. Every pipeline execution creates a Trial and every step execution creates a Trial Component. You can thus freely compare and track your pipeline’s performance over time.
A Callback Step was recently introduced to allow you to add functionalities not yet available in Pipelines themselves. To use the mechanism you first create and specify an AWS SQS queue. Then in a given step, pipeline generates and sends a token to that queue and waits until something sends them the token back (technically until that something uses SendPipelineExecutionStepSuccess or SendPipelineExecutionStepFailure APIs). Then you resume your pipeline. You can have another system like Airflow or StepFunctions consume the queue to perform a piece of work. This is a great and easy way to spin up an external workflow as a part of the original pipeline.
Additionally, a Lambda Step is available, enabling you to run arbitrary code on demand, as long as it finishes in 10 (not the usual 15) minutes. Be it a piece of small calculations or a tiny transformation job or a quick API call or a notification on Slack about the pipeline progress — just fire a Lambda.
EventBridge integration is also here. As a means of EventBridge triggering your pipeline you can either set your pipeline to work on a regular schedule or just trigger whenever some event occurs. On the other hand, your pipeline will also feed EventBridge as most of the Pipelines’ events are recorded. That means whenever a pipeline or a step state changes a corresponding event is sent to the default Event Bus for free. You can set up an EventBridge Rule and a Target to react on it, for example to notify you of failures.
Lastly, even though SageMaker Pipelines are not supported by declarative IaC tools like Terraform or AWS CDK, a handy method — upsert() — is available in the workflow.pipeline.Pipeline object. That method essentially means “create if not exists, update if exists” and enables you to (re)define and (re)deploy the service using Python. It is a utility and does not differ much from the usual IaC developer experience. You won’t be able to use it inside your ops repository full of Pulumi, CloudFormation or Terraform code, though.
Previously, we listed “no retries and no exception catching” as flaws and missing pieces of SageMaker Pipelines. As of 9 November 2021 both functionalities are here. You can fix your task and resume your pipeline without re-executing previous (successfully done) steps. You can also set up a retry policy to perform retries on various errors.
Oh, and they are also free. You don’t pay anything extra for them (but you obviously still pay for all other SageMaker resources that the pipeline spins up).
When should I use SageMaker Pipelines?
If your data scientists use SageMaker: pretty much always.
From a data scientist’s perspective SageMaker Pipelines conceptually do not differ much from Sklearn Pipelines or Spark Pipelines. The building blocks are just slightly “bigger” (transform entire datasets instead of one column and also spin up a machine in the process). If one uses SageMaker SDK on a daily basis, the learning curve won’t be steep and the learning process will feel natural. Most of the constructs used inside pipelines (Preprocessing Jobs, Training Jobs, HPO) are already used by your team. Pipelines just glue SageMaker Things together.
Data scientists always perceive their workflows as a continuous iteration over defined steps. (Re)define the business problem, gather data, transform it, give it to the algorithm, tweak it and try to get the best result. After performing initial exploratory data analysis and running first training jobs, they will naturally seek to organize their work and make it more reproducible.
And the SageMaker Pipelines will be there, waiting for them. Even when the workflow is bizarrely simple, why should you perform any manual (thus error-prone) work?
They were also designed as a tool for a data scientist and not your ops team. Their second purpose is to decouple and contain responsibilities between ops and data science teams in a sane way. The deploy step (and by deploy I mean “endpoint creation”, because batch inference is still available) was purposefully omitted, so that data science pipeline does not interfere with real-time production matters. Your data science team only marks that a given algorithm’s version is ready to be deployed. The ops team picks that information up and acts accordingly. As a supplement to the article, I strongly recommend watching this 20 minutes video showing SageMaker Pipelines (and Projects). You will immediately notice which pipeline (data science or operations) is responsible for what part.
When should I avoid SageMaker Pipelines?
There are some cases where it is not feasible to use them. Obviously, if your workloads are running outside SageMaker like in AWS ECS, Batch or Glue then Pipelines are out of question as they do not integrate with them. In that case, you will have to look into Step Functions (and the next article in the series).
If SageMaker usage is partial but you still juggle between Glue and SageMaker then Pipelines are questionable. It might work fine, if you are able to decouple data engineering and machine learning parts. First let Glue merge and wrangle the data in and out resulting in data ready-to-be-processed sitting in S3. Then use your machine learning tools wrapped inside SageMaker. You can even glue them together using EventBridge (new data on S3 produced by Glue could trigger your SageMaker Pipeline). But if juggling is constant, i.e. you move data between Glue and SageMaker back and forth several times then you’ll probably be happier with Step Functions.
Last but not least, SageMaker Pipelines are straightforward and simple. For many use cases, their simplicity is an advantage, as you can pick them up right away. But in larger workflows, where the DAG isn’t your usual “preprocess, train, register, be done” and consists of several hundred interconnected tasks instead, you will probably have a hard time using just them. They might still play a part in that workflow, but you will need another system to manage them, which one would name “DAG in DAG pattern”. Split your workflow into smaller, manageable SageMaker Pipelines and have another piece of software (like Airflow, Kubeflow or Step Functions) trigger and manage them. SageMaker Pipelines as of now, cannot trigger other SageMaker Pipelines - and even if they did, large pipelines are rarely using just SageMaker and you would hit the first problem mentioned (no integration with other AWS resources).
You may also be scared of using brand-new AWS services. Pipelines are not even one year old as of today and there aren’t too many examples or tutorials on how one should use it properly. The AWS community will be more likely to answer and aid you with your Step Functions or CodePipeline questions.
Amazon SageMaker Pipelines…
- is a tool for data science teams, not ops teams;
- combines Processing Jobs, Training Jobs and HPO Jobs in a logical what-happens-after-what pipeline;
- speeds up and automates your experiments after the initial EDA phase;
- is simple to use with SageMaker SDK and easy to pick up by data scientists;
- is free;
- is generally a low-hanging fruit for SageMaker-heavy teams;
- might not cover all production-related activities and require other tools to perform the deployment;
- has no AWS integrations with services other than SageMaker, EventBridge, SQS and Lambda;
- has exception handling and retry mechanisms;
- may be too simple for your needs if the workflow consists of dozens of tasks.
