AWS CodePipeline — the “original” machine learning orchestrator
Time to characterize the oldest tool in Amazon’s orchestration toolbelt — AWS CodePipeline.
 AWS CodePipeline
AWS CodePipeline

This is the third part of our “Serverless orchestration at AWS” series. Previously, we looked into two AWS services that can be used to automate machine learning projects — Amazon SageMaker Pipelines and AWS Step Functions. We recommend you familiarize yourself with them before continuing.
Wait, isn’t AWS CodePipeline a CI/CD DevOps-ish tool?
Mostly, but it also has other uses.
The application of machine learning in various industries is not that new with several years as a hot topic in many organizations. Companies invested in data science and many began building machine learning models with the premise of artificial intelligence solving all their problems.
Most companies lacked any idea about what a data science project lifecycle looked like. Even if they were mature i n software development, building a data science project required vastly different roles and methodologies across project management to succeed. So, they struggled, with their beloved scrum delivering an excrement instead of increment in each sprint.
The concept of MLOps was also pretty much non-existent back then. We generally lacked proper tooling - most MLOps tools of today are around 4 years old. If somebody did go to production, they used (at best) tightly coupled Docker containers running on bare machines. There was no Kubeflow and no Airflow. Luigi or Azkaban were brand-new things and tools like Oozie were too tightly coupled with Hadoop to be used outside its ecosystem.
AWS, as the leading cloud provider, could not ignore the MLOps trend and struggled to deliver a production-grade solution for customers.
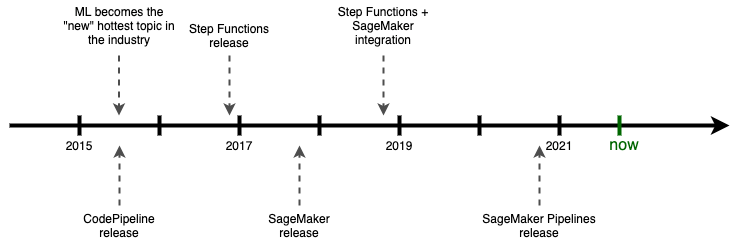
Due to increasing demand for solutions, articles and tutorials concerning productionalization of machine learning applications, AWS took their only existing tool suitable to automating pipelines and began creating learning resources.
Even though CodePipeline was not tailored to machine learning and was actually a tool created for DevOps, it still did the job better than running shell or Python scripts. Hence, many of their old re:Invent talks or Solutions Constructs used CodePipeline as the main building block of machine learning workflows. As clunky as it was, the tool paired with CodeDeploy (and CodeBuild later on) allowed new data science teams to structure their model building and deployment pipelines. Because SageMaker was not a thing yet, they mostly operated on containers or bare EC2 machines.
Then Step Functions came to the market in December 2016. As a general purpose orchestration service, it was initially not as feature rich as we see today. With the low maturity of the tool and SageMaker still-not-yet-invented, CodePipeline remained your go-to service.
Only around mid 2018, the tide began to turn. Amazon SageMaker - the machine learning platform in AWS - finally arrived and slightly matured, with Step Functions adding native integrations shortly after (i.e. a year later, duh). AWS shifted their narrative and started promoting Step Functions as the orchestrator we should all adapt and love. They even extended the tooling with SFN Data Science SDK in late 2019 and it seemed like Step Functions was here to stay forever as the only pipeline workflow manager we needed.
But, as the push to machine learning continued, this was not enough. A year after that, they revealed their newest invention - Amazon SageMaker Pipelines. They could finally announce the SageMaker platform as complete, allowing data scientists to build literally everything they need in their projects without leaving the SageMaker ecosystem.
And now we, the AWS customers, are left with three distinct yet similar solutions to the same problem — all offering a range of overlapping functionalities. Hooray.
The basics of CodePipeline
Like other tools covered in our series, AWS CodePipeline can be considered as merely a scheduler for other services. It performs little work itself and delegates tasks to various workers instead. A Pipeline in CodePipeline consists of a sequence of Stages.
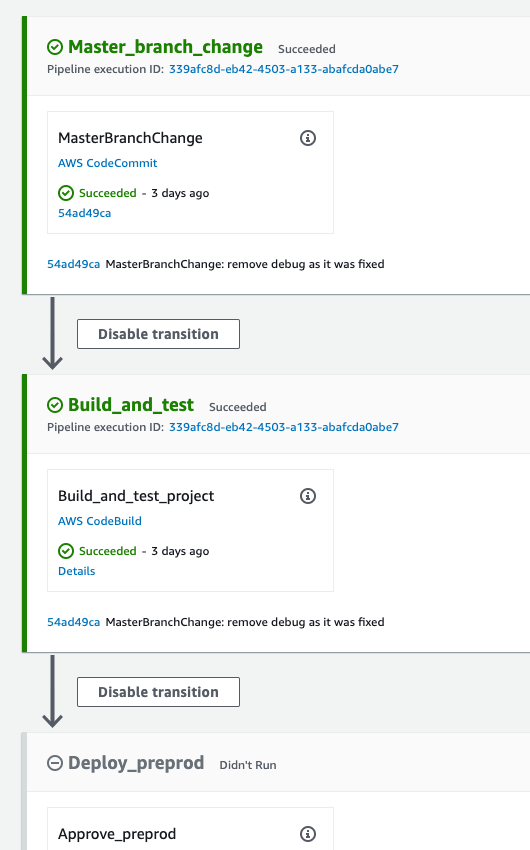
A Stage does not perform any work, but is rather a container for Actions. An Action is the actual work unit, categorized by what it does (there are Source, Build, Test, Deploy, Approval and Invoke categories). Every Action category has its own set of native integrations. Source Action integrates with GitHub, CodeCommit, ECR, S3 and similar. Build Action integrates with CodeBuild, TeamCity, Jenkins and others. And so on.
Usually, you define your general machine learning workflow as a graph of dependent Actions (preprocess data, train model, deploy model) and then group those Actions into Stages (qa0, preprod, prod).
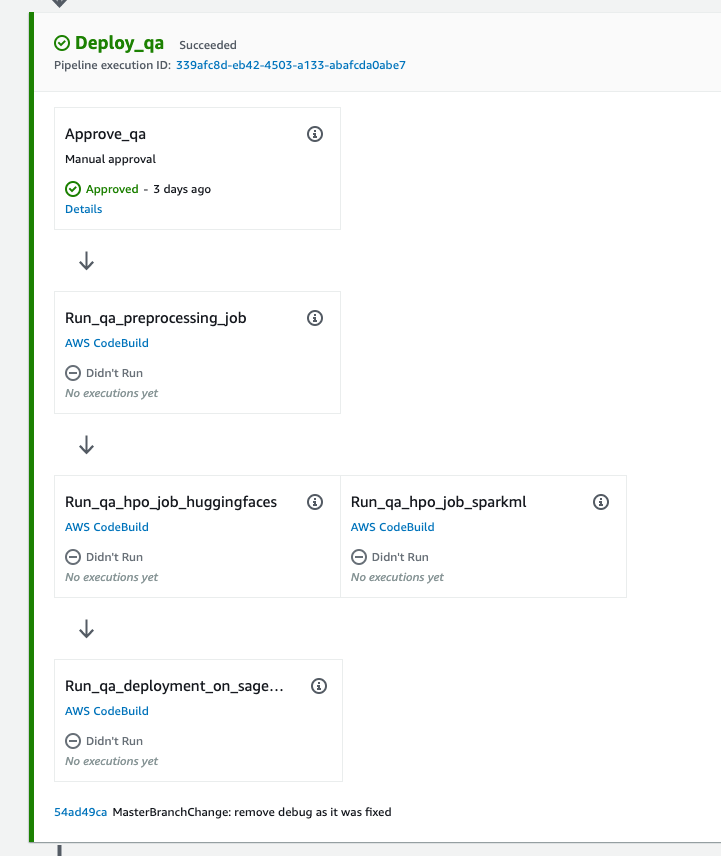
The big square Deploy_qa in the picture above is a Stage. Five lesser squares are all Actions within that Stage. Like Stages, they also form sequences, but every “level” of them (like two hpo_jobs here) runs in parallel.
Since the tool was designed to be a CI/CD pipeline for general applications, there aren’t many integrations tailored specifically to data science. Most of the existing ones concentrate on running various testing or deployment frameworks and tools natively. You probably don’t need them in your use case.
Your main building block will be a Build Action running CodeBuild. AWS CodeBuild is basically an EC2 machine running your build code. This code can be arbitrary — you are allowed to run any command you want to and also to bring your Docker container as a runtime for those commands. Thus, you can and will use CodeBuild to perform all your data science preprocessing and learning within the CodePipeline. CodePipeline will automatically spin up a machine (possibly a powerful one - you can have a large instance with GPU if you wish) to do the job of running your .py code and tear it down afterward. And then run the next one. And the next.
The second useful integration is CloudFormation provided via CodeDeploy. This one allows you to deploy your CFN stacks. You can code your SageMaker Endpoints with CloudFormation (or CDK) and then safely deploy it in CodePipeline. It is used in default SageMaker Projects in that exact manner.
You can also fire custom Lambdas with arbitrary code. You may also halt the execution until something (like an external system) tells you to resume it. This way you can extend CodePipeline with whatever functionality is missing right now.
CodePipeline natively supports running Step Functions too. You can do the basics in CodePipeline and delegate more complicated flows to Step Functions. CodePipeline will trigger them and wait until they finish to read their output. This pattern theoretically allows CodePipeline to become an orchestrator of the orchestrators.
The tool can be triggered by various sources. Git-related ones are self-explanatory, allowing you to rebuild and redeploy every time your code changes. A more interesting one however, is S3. You can start your build automatically whenever new data arrives. Other tools in our article series require coding a custom solution to achieve this (S3 events + Lambda).
You can also retry on a Stage basis without rerunning the entire Pipeline. You can fix your broken task and start the Pipeline from the place it blew up. This is really convenient if you spend some time-consuming computations. Which is especially useful when you set up your Stages so that each of them contains only one Action. This way, when for example the model building part of the pipeline blows up, you can retry it without having to perform data engineering scripts again.
They are also cheap. You pay $1 per one Pipeline per month as long as it runs at least once in that month. Additionally, the first month is free. You do pay for CodeBuild minutes, S3 storage and requests (CodePipeline stores the artifacts in S3 — make sure you set your bucket to expire objects after a few days) and other tools your pipeline is using though.
Lastly, since CodeBuild is effectively an integral part of CodePipeline, it is worth mentioning that it has a feature called Batch Builds. This can be used to run dozens builds at the same time with slightly different runtime parameters. Sounds familiar, doesn’t it? While we recommend doing HPO Jobs inside SageMaker, you could make them work here as well. This would probably require a custom Invoke Action with Lambda to select the best model and remove all others afterward. The feature is rather new and lacks proper documentation though, so be wary with your experiments.
The good, the bad and the ugly
Using only CodePipeline to perform the entire machine learning workflow means ignoring the 90% of native CodePipeline CI/CD-related integrations and just spinning up and down a bunch of CodeBuild machines running your data science code.
This is absolutely not a bad thing. If this is how your machine learning pipeline should look like (run some machines and be done with it), then CodePipeline with CodeBuild is probably the simplest way to achieve that goal. You can set it to watch your git repository with files like preprocessing.py or model_building.py and automatically rebuild the environment whenever a change is merged to the main branch. Or run the pipeline whenever your customer uploads new data on S3.
Additionally, this tool is also easy to pick up and is not tied to machine learning in any way. Your DevOps team will happily assist your data scientists with the productionization. The IaC support is excellent in tools like Terraform, CDK or Pulumi.
Alternatively, it could be used to delegate the model building to other tools and only handle the deployment part. Your data science team could use SageMaker Pipelines to prepare data and then the model for deployment, giving you sort of a blackbox to run. One CodePipeline would just trigger based on changes in SageMaker Pipelines code and execute them via CodeBuild. The second CodePipeline would then listen for the new model creation event (via S3) and do only the “redeploy SageMaker Endpoint” part, either via CloudFormation or other IaC tool of your choice. As mentioned previously, this is how AWS built SageMaker Projects. You can create a default SageMaker Project to see exactly how they wired all the components (two CodePipelines and one SageMaker Pipeline) together.

Summing up the good parts - CodePipeline will serve you well if your workflow is simple, and you don’t utilize clusters of machines or dozens of different AWS services. Or, if you can delegate the complex flows to other tools like SageMaker Pipelines or Step Functions and have only Ops operations performed in CodePipeline.
However, things do get more challenging as your workflow complicates. When delegation is not an option, you can forget about more complex features like branching or exception handling. CodePipeline’s simplicity comes with a price — customisation is hard. You could code some behaviours and “native” integrations yourself with EventBridge and Lambda, but that is an advanced task. You either praise whatever is possible and adjust your needs to CodePipeline’s limits, or you should abandon the tool.
Parallelization and concurrency is limited, since this focused tool was meant for deploying and building general purpose applications. While you can have multiple executions of CodePipeline running concurrently (for example deploying qa and preprod at the same time) and multiple Actions within the same Stage running in parallel (remember hpo_jobs in the picture above?), there can only be one running execution of each Stage at a given moment. This obviously makes sense as you wouldn’t want to perform a production deployment with two overlapping/conflicting versions at the same time, but rather deploy them in a sequence - but it limits you in the machine learning context.
If you want your Stage to be logical “try out this set of parameters and deploy them on an ephemeral environment” rather than “deploy a specific model on a specific qa environment” then your options are also limited. When you run multiple CodePipeline executions with different sets of parameters, they will just sit in an internal queue being processed one by one. You could clone your Pipelines to overcome this but this is rather an inefficient workaround.
The UI of the tool is also lacking and weird - it is vertical (instead of horizontal) and the UI elements are too large. There is a lot of scrolling up and down in larger pipelines to get a grasp of what is actually happening. Since CodePipeline is just a scheduler, if you wish to browse logs you will have to dive into another service like CodeBuild, CodeDeploy or Lambda with their own, different UI. This might be confusing at first, especially for people new to the cloud and not yet fluent in AWS Console.
Lastly, there is an important hard quota in CodeBuild you need to watch out for. A single build can take at most 8 hours. Anything more than that and it times out. This might not be sufficient for large models. Another obstacle is the fact that CodePipeline’s artifacts can have at most 5GB. As a workaround, you can just save your models directly to S3 in your scripts and only pass the references to that file as your artifacts.
The AWS CodePipeline service…
- Is a general purpose CI/CD tool for ops teams;
- Is very simple and can be used to automate simple workflows (run a few EC2 machines with your code in a sequence);
- …or it can be used to perform only the deployment part of MLOps pipelines (i.e. handle deployment of CDK/Terraform/CloudFormation of your SageMaker models);
- …or it can delegate complex machine learning model building parts to other tools like Step Functions or SageMaker Pipelines to become a “orchestrator of orchestrators”;
- Has few machine learning services integrations itself;
- Has some parallelization and concurrency abilities - make sure to test how they actually work;
- Currently, has a poor UI.
This was the third article in our series, briefly showing you the third orchestrator in the AWS cloud. The next and final part of our series will compare all of them in a classical SageMaker Pipelines vs Step Functions vs CodePipeline manner to help you pick the right tool(s) for your team and task.
