Scaling Amazon SageMaker for multiple teams
A guide on how to organize and secure SageMaker for use by many teams — from AWS Organizations to Amazon SageMaker Projects.
 Amazon SageMaker
Amazon SageMaker AWS Service Catalog
AWS Service Catalog AWS Organizations
AWS Organizations AWS Resource Access Manager
AWS Resource Access Manager AWS IAM
AWS IAM AWS IAM Identity Center
AWS IAM Identity Center

Amazon SageMaker is an all-in-one ML platform in AWS. It allows you to train, tune, deploy and monitor machine learning models using a combination of various SageMaker services. The platform is simple to use and lets you build projects rapidly. There are many resources, tutorials or workshops that show you the general idea and quickly make you productive.
What’s usually missing or only shown as the “next potential steps” is how you work within that platform as a full-blown data science team — or even better, as multiple data teams. After all, most products and projects expect and aim to grow rapidly. No matter whether you’re a data science software house with multiple projects for multiple customers, or you work at a product company and have multiple teams working towards the same goal, using SageMaker in a single person scenario is simple, but scaling it up across teams is a challenge.
Did you plan your SageMaker expansion accordingly? If you did not, you might find that your teams constantly reinvent the wheel, use wildly different tech stacks, don’t share insights nor knowledge and — last, but definitely not least — that the security of your solutions is lackluster.
If you and your team just started your AWS journey, you’re most likely not familiar with the term Landing Zone. You’re probably working on a single account and your setup might look more or less like this:
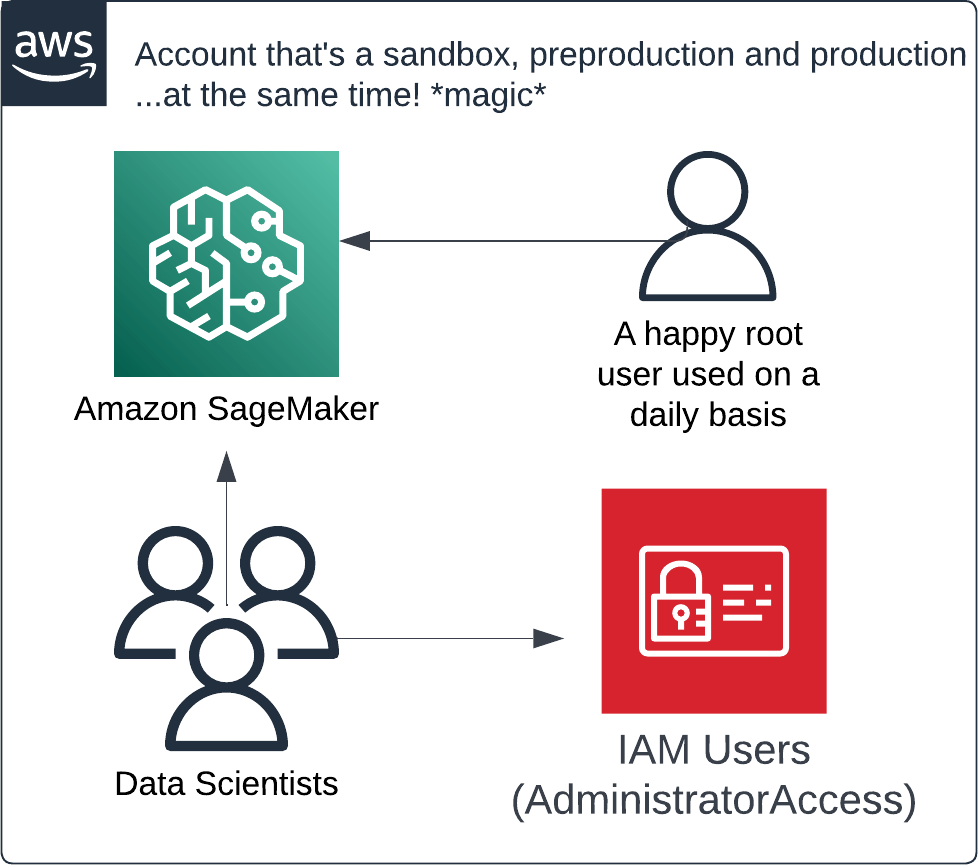
This antipattern of organizing access to services can work in the very beginning, but it simply does not scale — at least not if you value your sanity and money
While you can build your first prototypes just fine, and you might even bring something to production, it will quickly start to hinder your growth.
Instead, let’s see how we can go from a single user of Amazon SageMaker to access organized securely and efficiently across multiple teams. It turns out that scaling SageMaker for many teams is mostly DevOps-ish work and doesn’t require that much ML knowledge.
Overall organizational structure in AWS
Building larger projects on AWS usually means using multiple AWS accounts. A multi-account strategy is absolutely necessary to limit the potential blast radius of application issues and data breaches; to get a more granular, detailed cost breakdown of your environment; and to allow you to easily grant and revoke permissions to specific resources or projects.
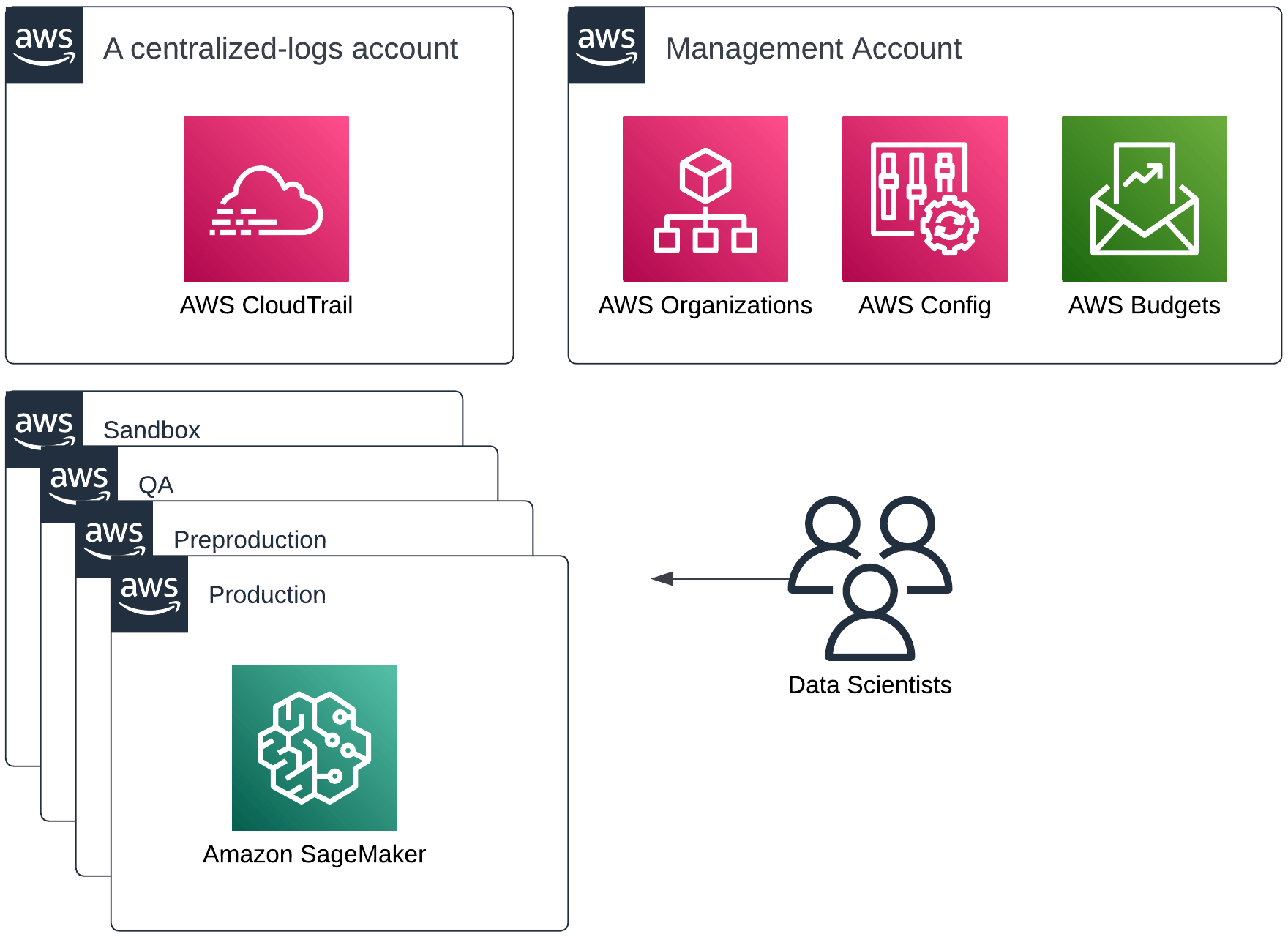
Multiple accounts organized via AWS Organizations with a single data science / machine learning team
AWS Organizations is the place to start on this journey. You can start with building just a sandbox, QA and a production account. When you’ve got multiple teams, you use organizational units to group your accounts accordingly. Some accounts will eventually be shared by all teams too.
Additionally, AWS Config can act as your inventory management solution. Amazon CloudTrail gives you visibility on who-does-what within your AWS environment (i.e. an audit trail). AWS Budgets allow you to set up automatic billing alerts. Last but not least, you can (and should) configure a SageMaker domain when bootstrapping your new account. All of these steps can be either done manually or by using AWS Control Tower — a specialized service to help you build Landing Zones.
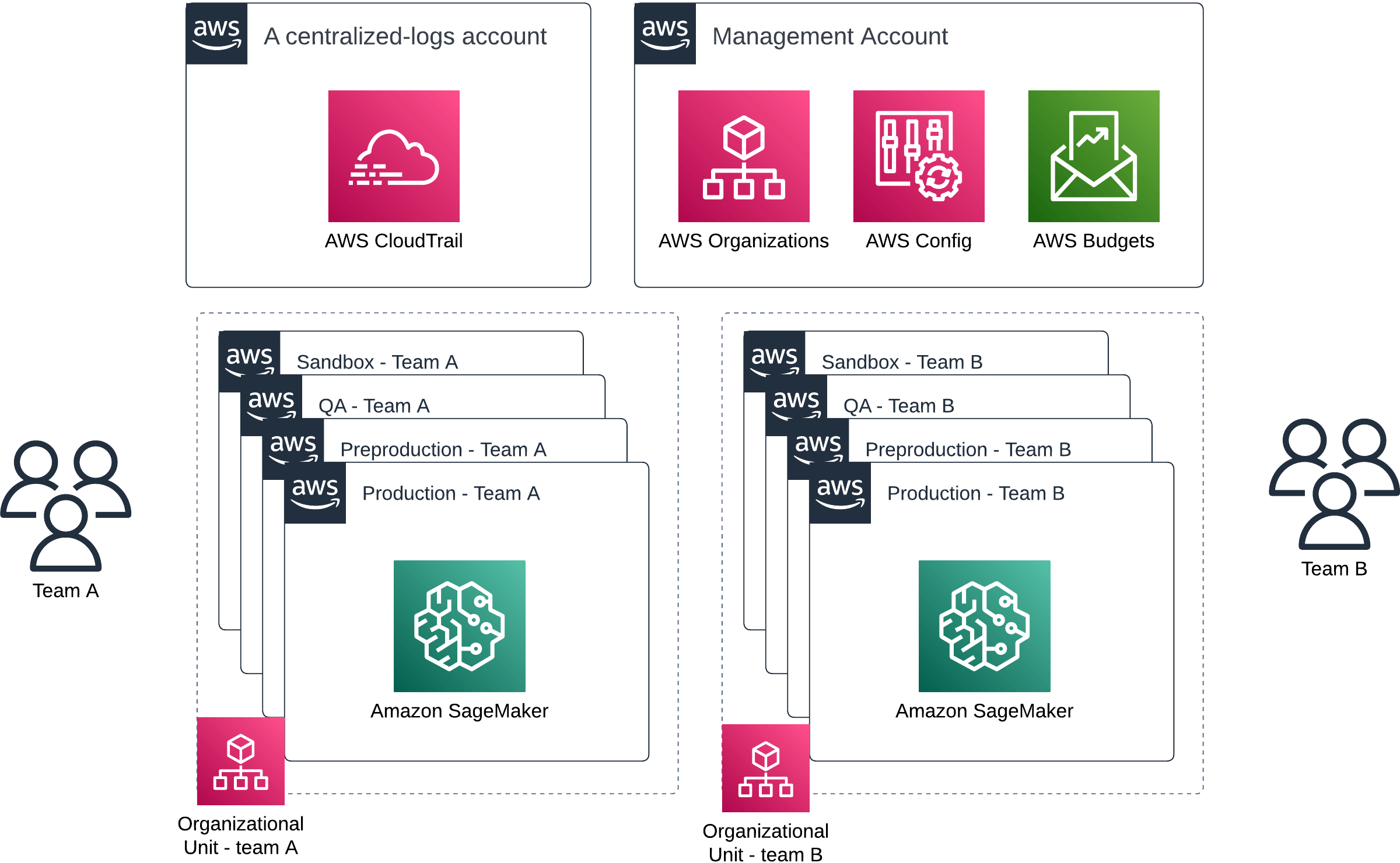
Multiple accounts organized via AWS Organizations with organizational units separating multiple data science / machine learning teams with access to Amazon SageMaker and their own environments
If you haven’t ever set up an organizational structure in AWS, we have a detailed article about setting up AWS Organizations with Terraform and a followup covering organizational units and service control policies.
Authentication and authorization
Now that your account strategy is in place, it is time to grant your data teams access to AWS. AWS IAM Identity Center (which used to be called AWS SSO) is a service that streamlines that process. This way you’ve got one central place where you create users and manage their permissions. No more juggling between various systems to allow a new person to access a specific resource. Everything is in one, slick UI.
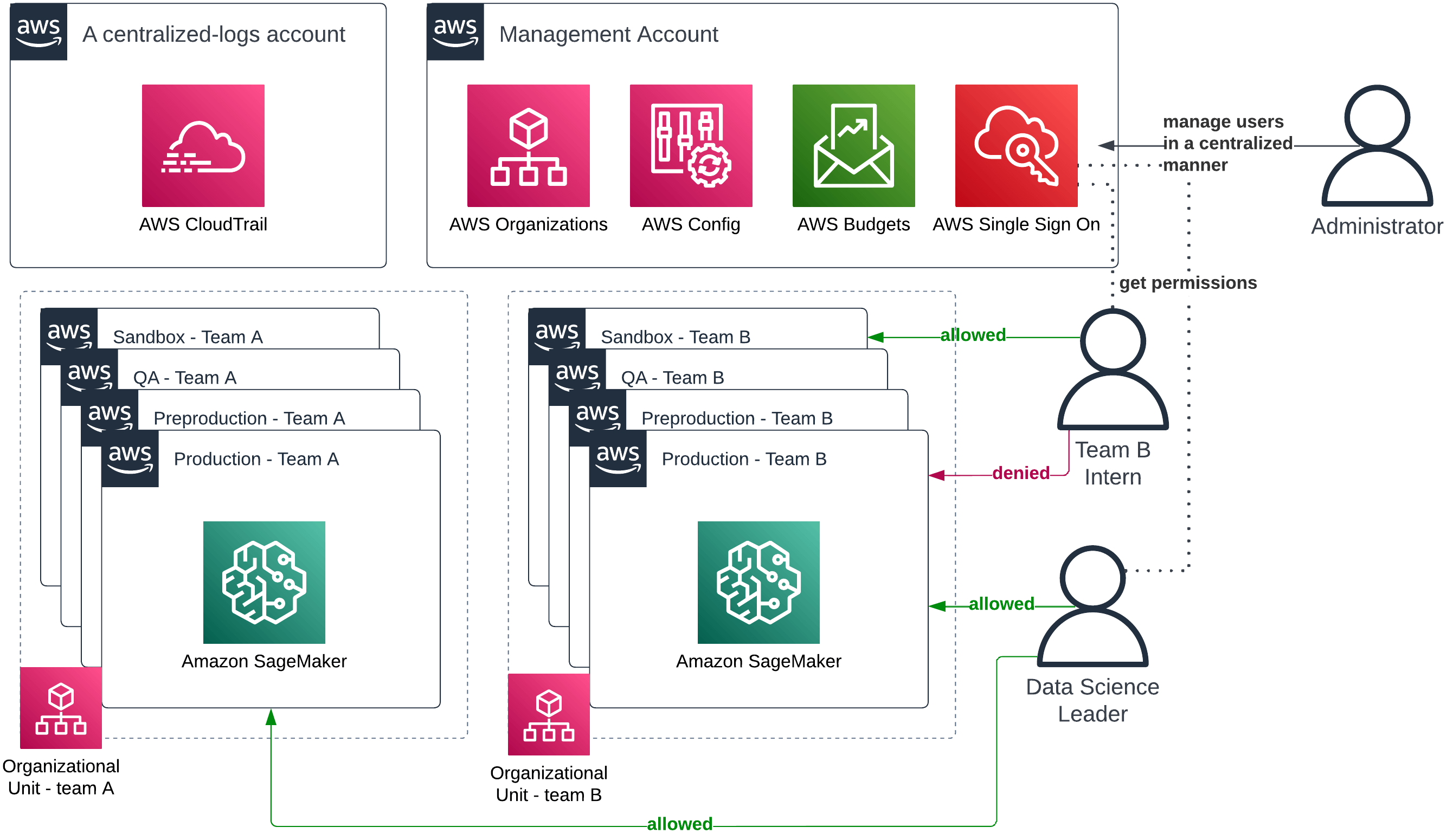
An example authentication and authorization flow granting access to AmazonSageMaker for multiple teams and roles
With some additional work, you can integrate AWS IAM Identity Center and Amazon SageMaker so that you can select which user belongs to which team, and is allowed to perform which actions. If your company has strict security and VPN usage policies, you can also restrict access to SageMaker to people connected via your VPN (and thus to AWS). This provides another layer of security to the solution.
You could also synchronize identities in AWS IAM Identity Center with your external identity providers, such as Azure AD or Google Workspaces, to streamline actual identity/user management.
Sharing resources across accounts
Once we’ve applied separation with AWS Organizations and proper authentication, your teams can work in secure, isolated environments with limited blast radius and least-privilege principles in action. However, isolation also severely hinders the ability to transfer knowledge. It turns out that data science teams often want to exchange something. Be it models, pipelines or libraries — you need a way to enable this flow of resources to foster productivity and collaboration.
Thankfully, AWS IAM and AWS Resource Access Manager (AWS RAM) come to the rescue. You can use one of AWS IAM’s basic features to delegate access to some resources on a given account to principals from another account. In other words, we let specific people from account XYZ access specific resources at account ABC. You can share literally anything between multiple AWS accounts.
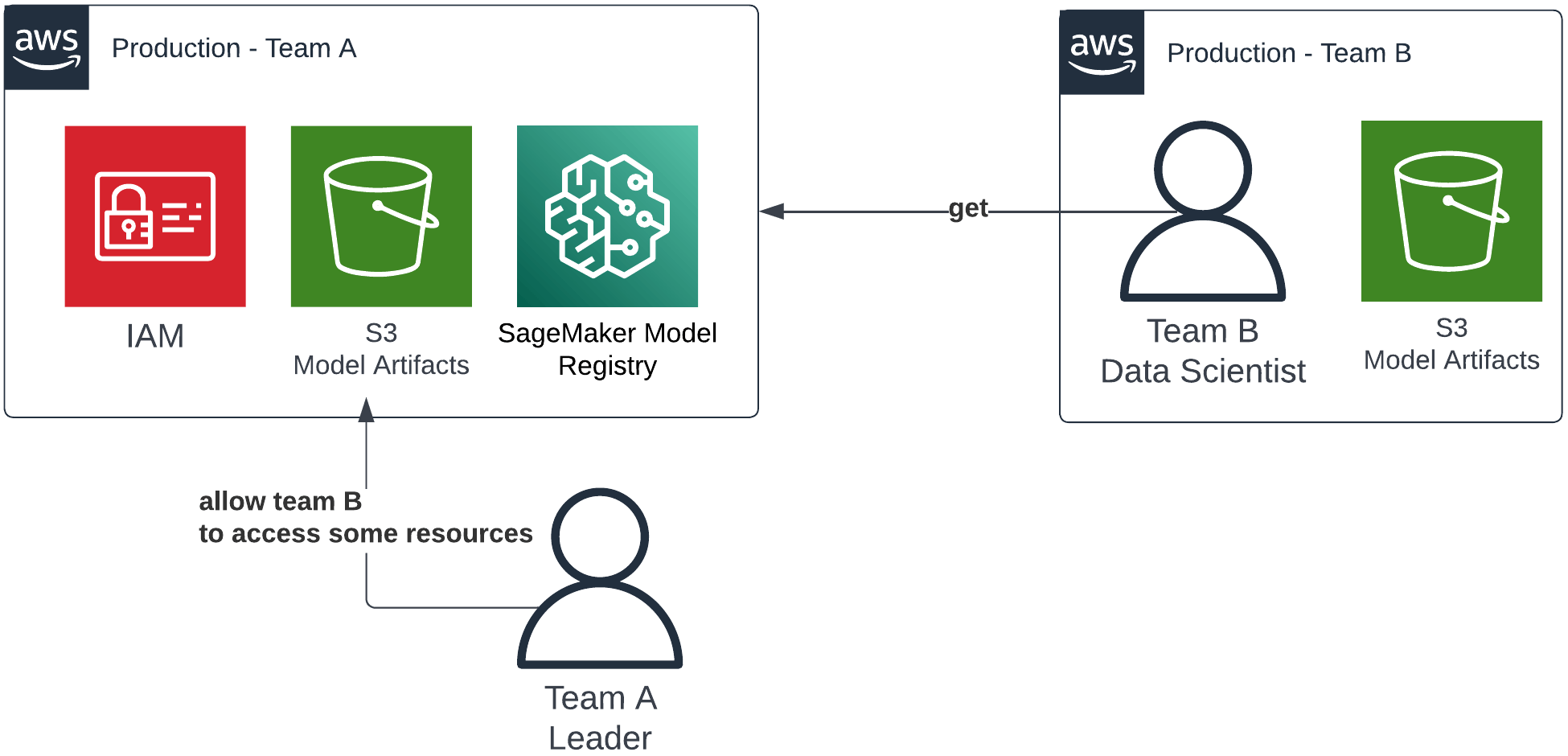
An example of how shared access to specific resources could be structured using AWS IAM
This feature alone lets you build proper multi-account deployments. For example, a shared services account can run your CI/CD system and orchestrate deployments across many other accounts such as dev, preprod or prod. Or, teams can exchange datasets, models or entire feature stores.
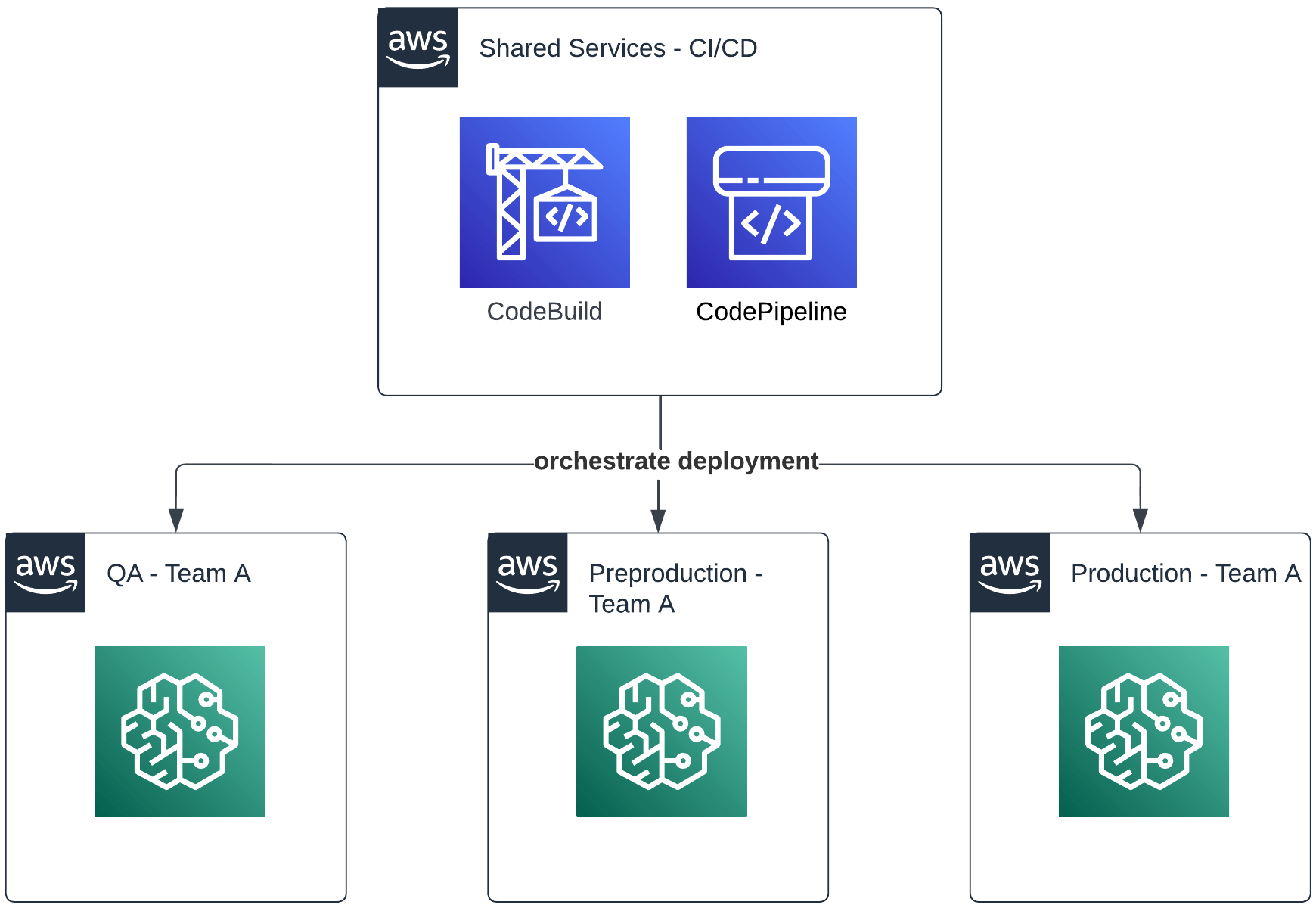
An example of how access to shared services could be structured using AWS IAM
AWS only recently started to improve these sharing capabilities by adding AWS RAM into the mix. This service makes the process even simpler and provides a handy UI in which you can share and browse shared resources. Currently, this only supports SageMaker Pipelines.
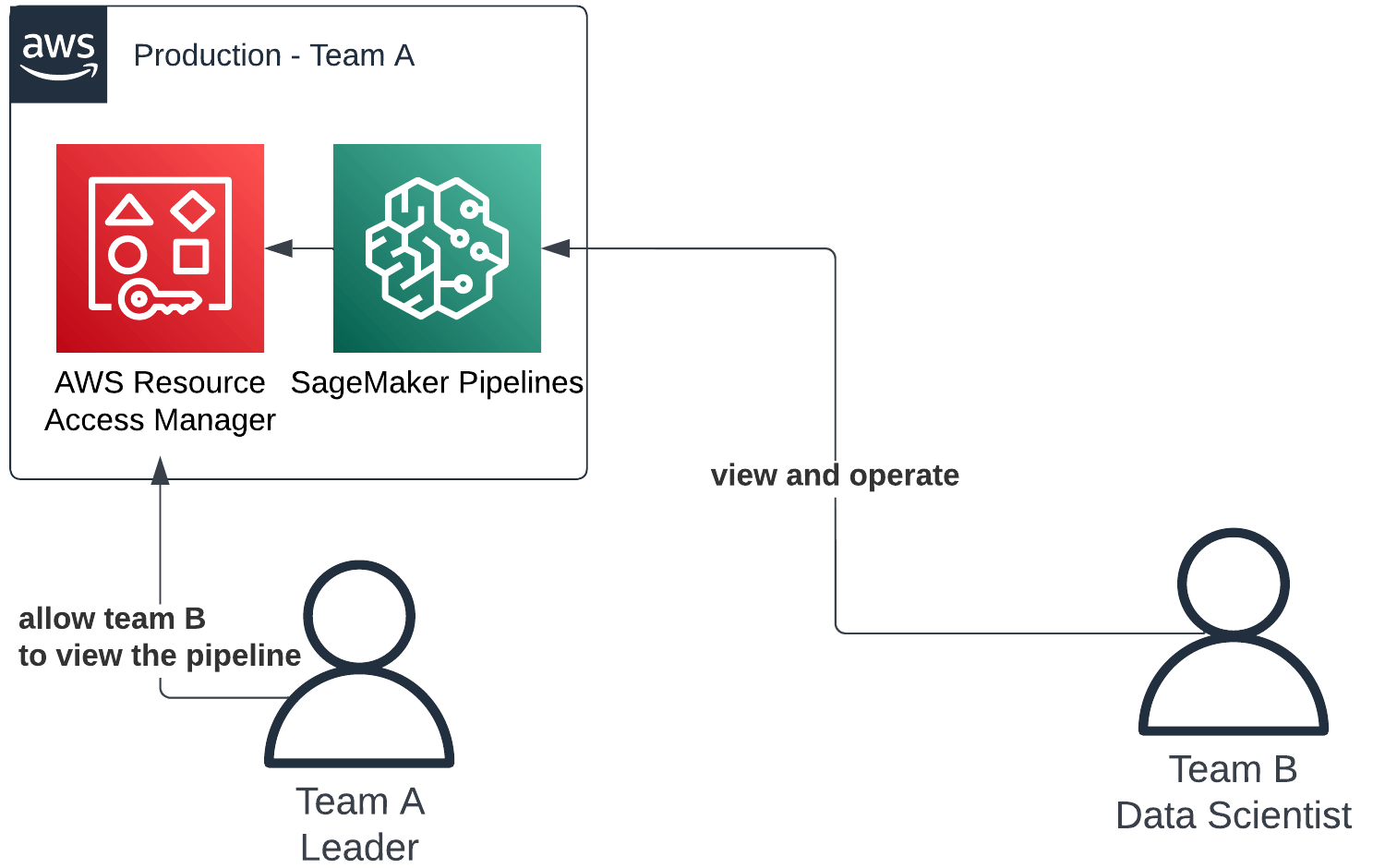
An example of where AWS Resource Access Manager fits into our resource sharing flow
Sharing solutions with AWS Service Catalog
The setup above lets us work in an organized manner and share resources safely. However, there’s still a lot of wheel reinvention that may occur. Spinning up and bootstrapping a new idea or project might take a lot of time. The reuse of code and patterns may remain a challenge.
To overcome these issues, we’ll introduce the concept of a service catalog. A service catalog is a place where you store, catalog and maintain ready-to-use technical solutions for your organization. Think of it as a place in which you store the blueprints for solving various tasks: e.g. “a template that deploys a containerized app”, “a ready-to-deploy data lake” or “a basic VPC networking configuration”. Some teams provide and maintain these solutions to retain business and technical knowledge, while others just consume and use them.
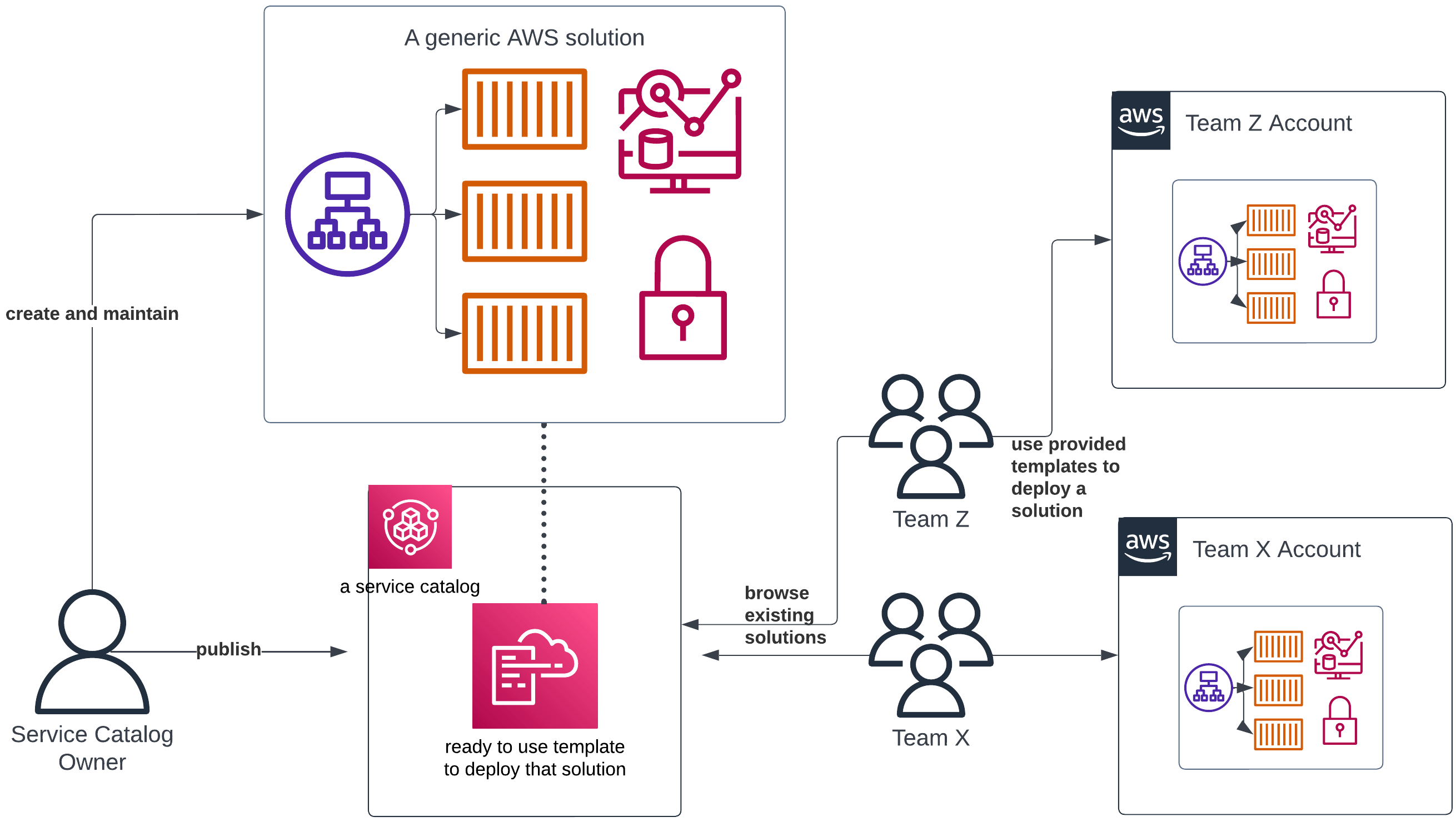
An example flow with AWS Service Catalog facilitating the reuse of existing solutions across an organization with multiple teams
This concept is implemented in AWS. First, a service called AWS Service Catalog was created that let you store various templates of preconfigured AWS resources and allowed other people to deploy them in one click. A couple of years later, SageMaker Projects service was built, which basically let you access ML-specific blueprints and solutions from AWS Service Catalog within SageMaker itself.
These are the key technologies if you plan to expand your SageMaker capabilities. If you plan to stay purely on AWS, you have to invest in them heavily.
Templates in Amazon SageMaker Projects
SageMaker Projects come with some premade templates from AWS that show you how to build basic solutions formed out of various SageMaker components. A great starting point is the template with model training, tuning and multienvironment deployment, all automated via SageMaker Pipelines and CodePipeline. A full-blown example production setup can be deployed in a matter of minutes. Then, with a couple of tweaks here and there — you basically swap their hello-worldish model building code with your own, and your system could be classified as production-ready.
Afterward, you will slowly tweak these out-of-the-box solutions and implement your own variations, to meet your specific use cases. There’s a handy AWS managed git repository which contains a wide range of custom templates. They consist of some CloudFormation or CDK templates of various SageMaker resources and instructions on how to push these templates into your AWS Service Catalog and SageMaker Projects. This makes it a great place to learn how to build custom templates in many different scenarios.
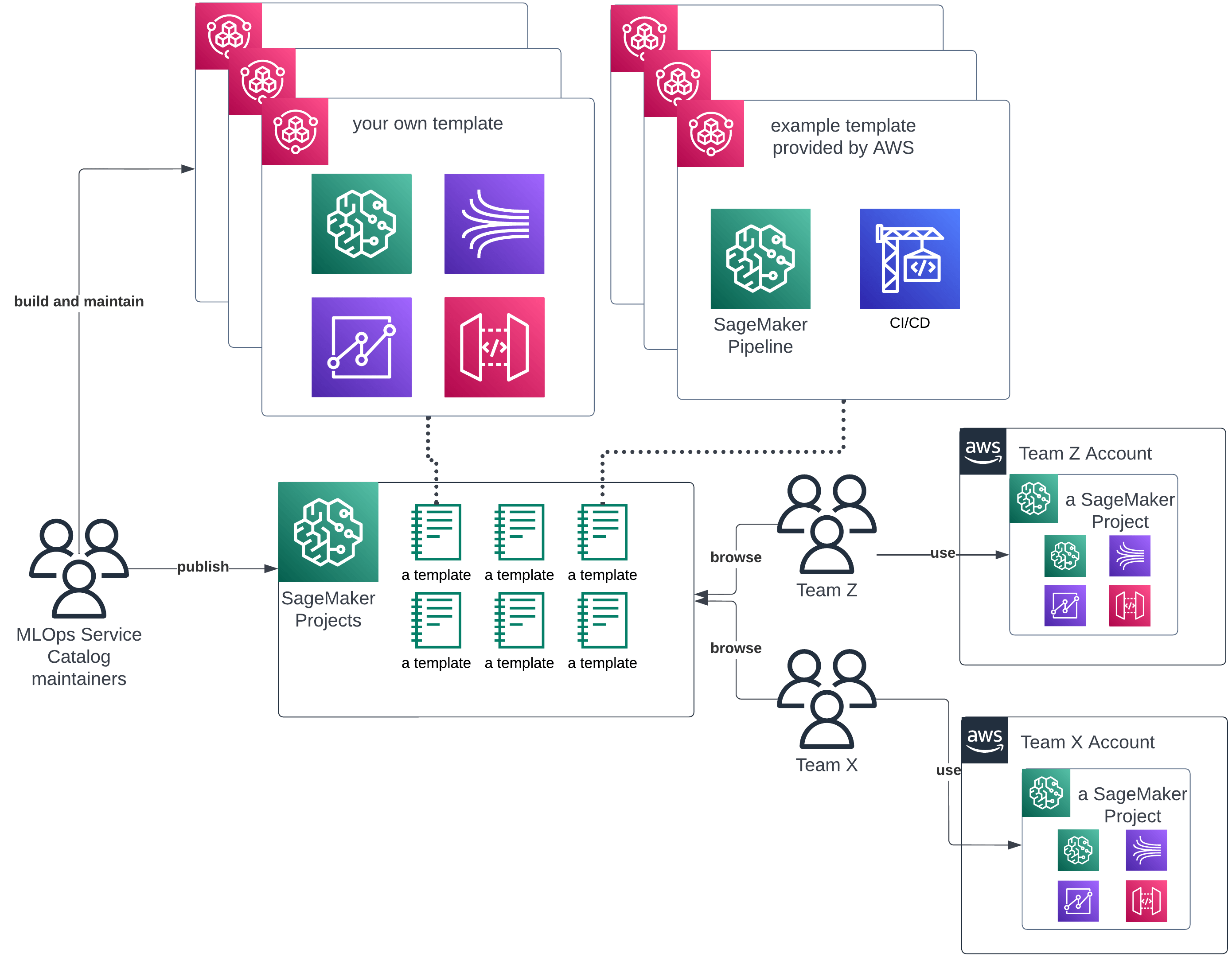
An example of how templates of Amazon SageMaker Projects fit into a resource sharing flow across an organization
If implemented and used correctly, SageMaker Projects is a powerful tool. A new project or even a new team can be bootstrapped in minutes. Any enhancement that one team produces, can be quickly transferred to a SageMaker Projects Template and then deployed to all other teams, streamlining work for everyone. And finally, when people switch teams, then the general idea and the MLOps stack stays basically the same. They don’t have to spend months onboarding into another project.
Libraries and technologies
Now, for the glue parts. To maintain development velocity and not drown in technical debt, a lot of general, good software engineering practices must be applied. Starting with developing a strict code review process, having automated CI pipelines everywhere, using code linters, formatters and static code analysers, your codebase must be well maintained.
Infrastructure as code (IaC) and configuration as code (CaC) are absolutely essential for your teams to survive. They’re the tools that let you reuse patterns between multiple teams. Investing in them and in ecosystems around them (IaC and CaC code can also be scanned, linted and reviewed!) will pay off in the long term. If you choose not to use them, you will lose the ability to manage and operate your infrastructure at scale.
Unfortunately, at the time of writing, SageMaker cannot be fully configured using solely usual IaC tools like Terraform or CDK. You have to mix IaC with SageMaker SDK which usually means “create the backbone of the infrastructure with IaC, then run your SageMaker SDK scripts that create the rest of the stack, using a CI/CD pipeline”. This is what most SageMaker Projects Templates currently do. But, even with these minor inconveniences, this still tames SageMaker and makes it manageable.
Your data scientists might find some parts of the SageMaker SDK too verbose. For various reasons you might want to use a different service somewhere — for example, a different experiments tracker or models registry. Or, some of your data science workloads might be very similar, not only on the infrastructure level but also in data science code. All these situations deserve creating your own, custom internal library to speed your teams up. This does not mean creating your own PyTorch, but rather having a standardized boilerplate that configures something with a single line of code. You can use AWS CodeArtifact to store your libraries.
Lastly, even the structure of the Git repositories that you’ll inevitably create can be automated. Tools like Yeoman or Cookiecutter streamline that process. You can use them to have a standardized way of how Git repositories are structured (naming conventions, catalogs, adding preconfigured utilities such as pre-commit). These technologies, paired with SageMaker Projects, help ensure that every team follows a similar workflow.
General organizational tips
Last but not least — scaling SageMaker up for multiple teams is in many ways no different from scaling any technology to work for multiple teams.
What might be challenging is balancing a given team’s autonomy with some imposed, general rules and frameworks. One of the most important principles of DevOps (and MLOps) states “you build it, you run it”. If you force your “general” technologies and solutions on every team too much, you’ll severely hinder their abilities to own their work. Instead, silos will be built and responsibility will be scattered and blurry.
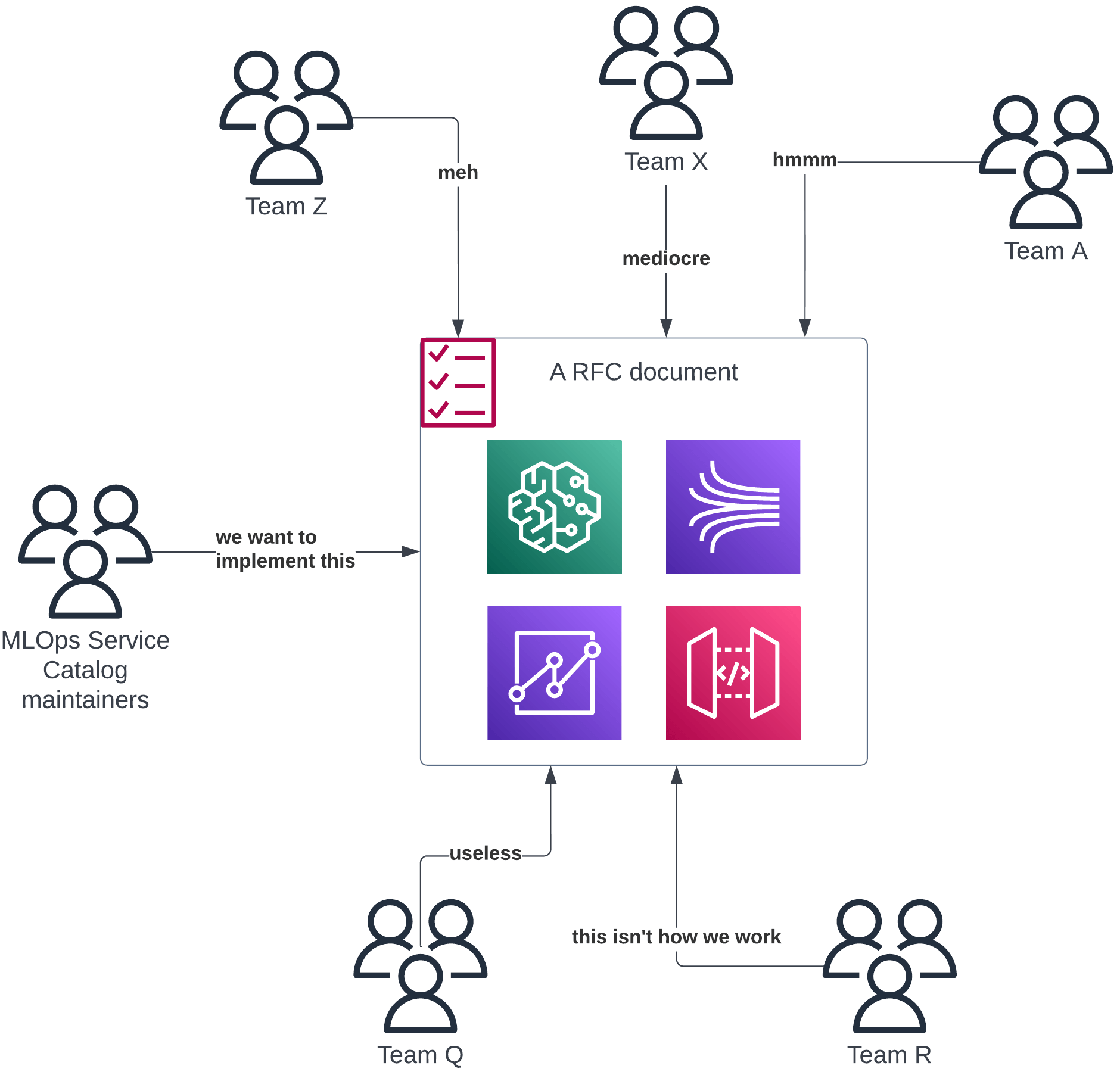
Instead, listen to and observe what each team does internally. Ideas should come from the bottom, i.e. from these teams and not from some centralized platform team that manages everything. Use these IaC and CaC techniques to move a good idea from one team to all of them.
Before you implement anything on a central level — gather all teams and discuss ideas in meetings or RFC proposals. Witness those ideas get destroyed and laughed at… and then watch how even better solutions get proposed in response.
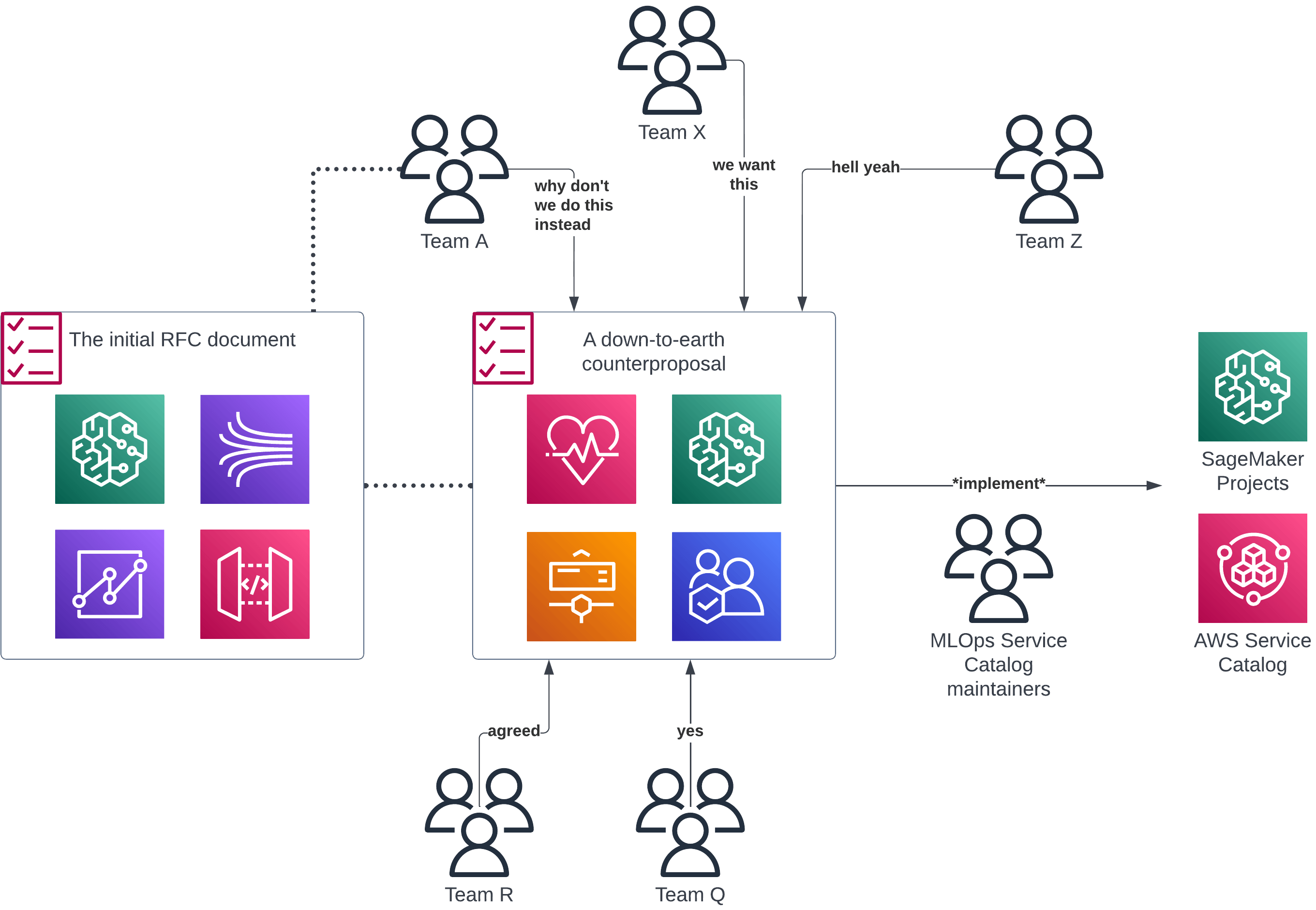
Summary
Scaling SageMaker is not a simple task and should be tailored to the needs of your organization. If you’re just starting out, focus on building a proper AWS Landing Zone structure first, then estimate how much your data science needs will grow in the following quarters.
Additionally, start using SageMaker Projects with AWS-provided templates to get accustomed to the idea of a service catalog. Then, after splitting your workloads to separate accounts, you’ll inevitably hit some permission/access issues, which you can solve with cross account resource sharing mechanisms. Lastly, develop your own tailored SageMaker Projects templates and various helper libraries.
At all times, focus on the developer experience and ensure that you’re streamlining the process for your teams and not forcing something useless upon them. Some features and services make sense only at a certain scale (for example several teams all running production models) — using them from day one often increases complexity for little tangible benefits. Always discuss your ideas with the wider audience.
Oh, and AWS recently released a somewhat complementary whitepaper to this article. Give it a shot too!
