
A comparison between three AWS technologies used to automate workflows in machine learning projects.
This will be the last article of our “Serverless orchestration at AWS” series. In the previous ones we have defined an orchestration task in machine learning and pointed out three possible AWS services providing the solution. We have reviewed SageMaker Pipelines, Step Functions and CodePipeline. Since you are now quite familiar with all of them, we can now proceed with detailed comparison and sort of TL;DR of the TL;DR. We will try tackling all kinds of questions like “which orchestrator should I use” or “SageMaker Pipelines vs Step Functions”.
The automation and toil removal is an essential core principles of DevOps methodology. Since MLOps is a spin-off of DevOps, we also apply that principle here. All steps you perform while training, tuning and deploying your models are time-consuming and error-prone. If there’s no automation, a lot of time, effort, energy and - most importantly - the human potential is just wasted. You can not allow that in your projects. Hence, a proper choice of orchestration service is crucial.
Generally speaking, it is often tempting to add yet another shiny tool to your technological stack, no matter whether you develop data science, web applications, cloud infrastructures, mobile apps, games or whatever else. What you see on most landing pages or sponsored articles and hear at conferences always seem to solve most of your current issues. But in the ever-changing landscape of IT technologies, if you added a brand new tool every time you’d see one fitting, you would not have time to actually deliver anything useful. Technologies come and go, but in the long run you need to stabilize and work with what you’ve got.
We know that it is very tempting to have a huge, fresh and modern stack. It for sure was for me, when I first started dreaming and then designing my first systems. The more logos added, the more professional it looks. But then, deploying that system would require a tremendous effort, not to mention the maintenance, onboarding and general team building problems which would arise shortly after. Whether you like it or not, you have to focus on building useful business systems and not tinkling overengineered behemoths.
Additionally, a modern stack quickly becomes outdated as the problems solved by your current tool also introduce new ones. So another wave of technologies comes to solve them, bringing new issues in the process. And so on.
As the time flies, it does not get any harder to add something. However, if you wish to remove or replace a tool, things get more challenging. Downstream or upstream systems are dependent on your previous technology and you can’t just get rid of it. Suddenly, a slight change might take you weeks or years, due to a tree of dependent services.
But then, if you always used your old toys, you could become obsolete in a few years. Problems you tackled five years ago differ from the ones tackled today. While tabular data can still be successfully analysed with XGBoost, if you for example do work in the NLP field then you probably have to replace your flavour of BERT every couple of months with a newer version from huggingface library. Similar progress was achieved in forecasting or computer vision. If you used models from the past there, the results would be at least lacking and you could quickly go out of business.
AutoML tools grow, day by day and some data scientists are afraid of them. Modeling is now partially solved, at least for some tasks. A data scientist spends most of their time on strict data wrangling related tasks. Which, either a MLOps engineer or a data engineer with a strong software engineering background will probably do in a faster, cleaner and more maintainable way. If they don’t have new tricks in their pockets, they might be genuinely scared of becoming meaningless.
Your team also needs to grow. They need to enjoy their work. Happy team grows. Sad and depressed one decays. A new technology to scout out and introduce is usually a fun task for most people.
You will have to balance the happiness and growth of your team and limits of current technology versus stability and familiarity of your existing stack. You don’t use new tools only to keep pace with the rest of the IT world and please your team. You use them to solve problems in a better way.
Thus, as a first step you should define what kind of features you need and, perhaps more importantly, which ones you do not need. While running large clusters with hundreds of tasks may sound sexy, this is often not needed. Likewise, integration with other AWS tools is a reasonable request only if you actually do use these AWS tools. If you don’t know how to define the exact requirements for your orchestration service, this is the place where a two hours consultation call with a more experienced person could save you thousands of dollars in the long run.
Only after you feel what your expected solution should look and work like, can you research whether your team or organization has any experience in the area. Keep in mind that orchestrating tools are just workflow management tools. Your colleagues could have used them in different contexts than you think. Your data science team might have never used Step Functions, unlike your software engineering team. Similarly, Argo Workflows may be well known and widely used within your devops team. You could use their expertise to quickly get you started and push to the extremes what your organisation already knows.
If you are uncertain about a technology, give yourself a day to try it out. Most of them have a well written “example pipeline with XGBoost” tutorials with Jupyter Notebooks ready to set everything up.
Additionally, do note that most of us like familiarity. We like when our existing toys fit with new ones. There’s absolutely nothing wrong with that. If you are a Kubernetes savvy company and have to tackle a new problem, then you will most likely start digging “how to solve X in Kubernetes” first. Likewise, OSS-first organisations will look out for open source, vendor-lock free solutions. AWS shops will seek AWS solutions.
Thus, another important dimension to look for is “the goodness of fit in your current stack” of given technology. Keep in mind that this is also a double-edged sword. As Rich Hickley, the author of Clojure language in his famous “Simple Made Easy” talk has said - “if you want everything to be familiar, you will never learn anything new, because it can't be significantly different from what you already know and not drift away from the familiarity”.
The point of these paragraphs is absolutely not to discourage the idea of adding new tools entirely. This would be completely absurd. We just suggest a pragmatic approach before a technology is introduced to your project. Always ask yourself questions like the following ones - does it solve my exact problem or twists it in some way first? What other problems will it introduce? Will we save time in the long run if we use this? How hard will it be to pick up for a new person? Can a fresh graduate understand it? Is it just a one man side project or a company backed technology? Can we extend it and add the functionalities it will be missing? Is the project we are working on a mission critical one and experimenting on it would be dangerous?
Hopefully previous articles and paragraphs made you reconsider your needings and define exactly what you do require. We can now safely proceed with comparison of SageMaker Pipeline versus Step Functions versus CodePipeline.
We will first rule out the easiest technology. CodePipeline, the least machine learning connected technology, makes most sense only in two specific use cases. The first one is as follows:

If all you need is a compute power in a simple workflow without other AWS services and managed by your DevOps team then CodePipeline is probably your solution. This is the easiest way to run a sequence of data science scripts. Be wary though, that CodeBuild has only a handful of machine types (how much CPU, RAM and disk spaces they have) available. The one with GPU is rather gargantuan.
The second use case comes straight out of SageMaker Projects idea. If your workflow is still simple and you still have a DevOps team partaking, but you use SageMaker heavily then you can have both groups (data scientists and devops engineers) create black-boxes for each other by using two different orchestrators.
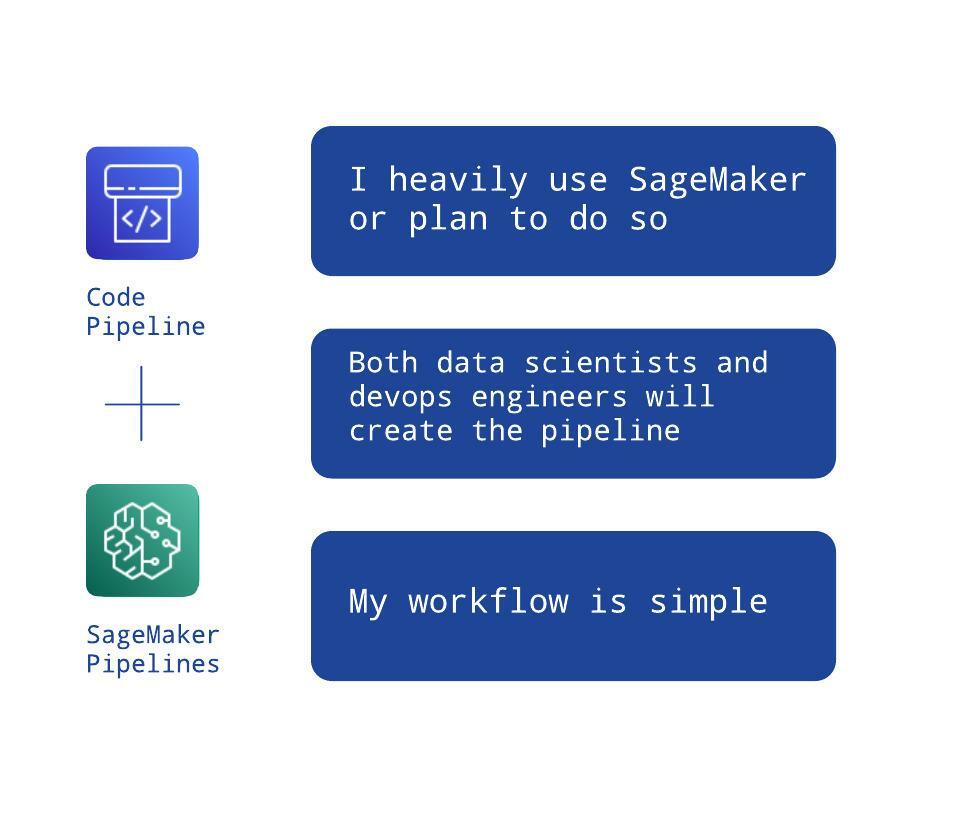
SageMaker Pipelines are sometimes referred in the AWS documentation as SageMaker Model Building Pipelines. We think that should have been the default name as only this name fully reflects what they actually do. Your data science team will create a pipeline that results in a trained model. That model will be picked up by the DevOps team with CodePipeline and safely deployed (...and you could swap CodePipeline for your existing CI/CD tool if you wish). Two teams can work in an organised manner and neither of them requires knowing the exact “domain specifics” of the other. And yet, the result will still attain the highest quality.
Moving forward to the Step Functions zone. As mentioned in their review article, this service is way more developer oriented and it should be easiest for either machine learning engineers, data engineers or cloud software engineers to pick them up. It would be best if you had those roles in your team.
Do note that, this is by no means a diminish of skills of other roles in a cloud data science team. Everybody can learn and use anything with great results. But similarly how a data scientist will instantly get what SageMaker is about or a devops engineer will be the first to understand VPC, Transit Gateway and other AWS networking tools, Step Functions were tailored for software development and software development related roles are their main audience.
With that in mind, let us start with easy choices for Step Functions. If all you do is orchestrate containers and you don’t care about SageMaker then there is only this tool to solve it. Scheduling arbitrary Fargate or Batch containers can easily be done here.

The same case occurs if your workflow is very complex and you heavily rely on other AWS services like the data engineering ones. Step Functions is the best service to assist you with its native integrations and the capability to call AWS SDK.

But, since Step Functions are designed to be split into lesser workflows, you may choose not to burden your data science team with exotic libraries and let them stay in SageMaker’s realm. This is similar to the first use case described, where data scientists built a model building black-box to be used within other tools. In this case, we could just replace CodePipeline with Step Functions since the flow may be too complex to handle by CodePipeline.
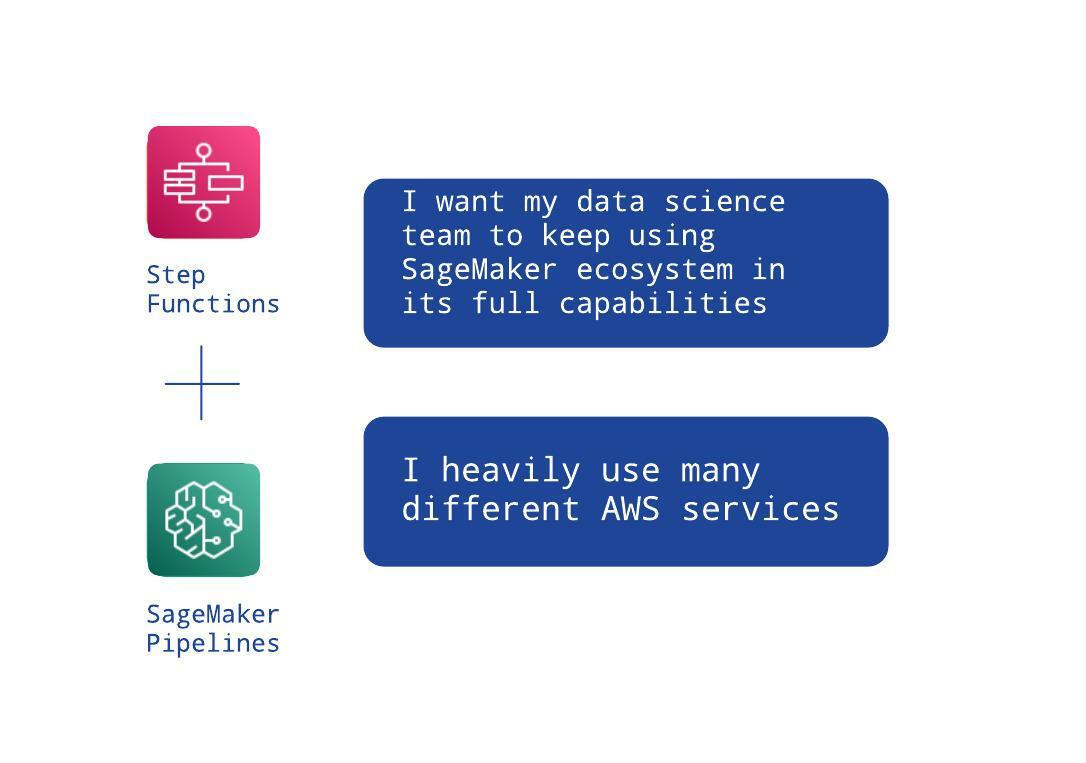
This has both pros and cons - you have two separate tools (but with clearly defined boundaries) instead of one, but your data scientists do not leave their comfy SageMaker zone. It also requires coding a (well documented) callback pattern, because Step Functions have no native SageMaker Pipelines integration yet. Unfortunately, that means more work for you.
Finally, pure SageMaker Pipelines. For now they do not support native Model Inference deployment, so there is a limit to what can be achieved with no other “assisting” tools.

An obvious must is that you are working inside SageMaker with all its goods and your workflow is not a very complex one. You just have a sequence of SageMaker Jobs resulting in a trained model. If that is all you need (for example another system takes your compressed model files and you do not care what happens next) then SageMaker Pipelines are sufficient.
A second use case would be running batch offline predictions as a last step of the sequence. This too can be achieved with solely this service.
Summing it up, an opinionated decision tree can be drawn.

Finally, an important note must be made. Since all three services are natively integrated with Lambdas and have the ability to halt the workflow until something else resumes it, you could theoretically extend them however you want to. Running SageMaker Jobs inside CodePipeline. Integrating StepFunctions with SageMaker Experiments. Scheduling EMR Jobs in SageMaker Pipelines. All that is possible, as long as you have infinite resources to create and maintain an advanced and strictly technical code.
In reality, orchestrating is an implementation detail. And it should be. Obviously, the pipelines you create should be production grade, rock solid, observable, reproducible and so on. But achieving their highest quality should require as little investment of time and effort from your team. You should probably focus on meeting the business goals of your data science project instead of spending weeks extending functionalities that bring little to the table.
Choose a tool that both satisfies your requirements and needs the least amount of time to spend on extending it.
Here comes an epilogue and sort of bonus scenes of the series. If you asked a large company how they manage their workflows, an usual response, even if that company was an avid AWS user, would rarely contain the technologies we have mentioned.
Because sometimes, none of those tools will cover your needs. When you have really complicated workflows with hundreds of thousands of jobs to be performed daily, when you need to really extend the capabilities of a tool or when you really can’t lock yourself too much in the cloud and all you can utilise is its elastic compute power then you probably can’t utilise the AWS goodies.
I once worked on a project that spun off hundreds of machines, all running differently configured containers. It also happened to be a SaaS so each customer had their own, different structure of the graph of task dependencies. As much as I love AWS offerings, I can’t imagine using Step Functions to orchestrate that. A more advanced tool was required.
And such tools are already here. Airflow or Kubeflow are the most common examples, used in companies like Airbnb, Lyft or Walmart. If you thoroughly reviewed all three AWS serverless orchestration offerings and all of them seemed lacking, then you should look into more advanced technologies like the ones we just mentioned. Keep in mind though, that you will need to manage and customize these systems yourself. There is no free lunch.



We'd love to answer your questions and help you thrive in the cloud.






